AI Agent到底是什么
在说具体案例之前,先把AI Agent这个概念讲清楚。
传统AI的工作模式:
你问一句,它答一句。每次交互都是独立的,上下文无法跨会话保持。
AI Agent的工作模式:
你给一个目标,它自己规划步骤、调用工具、完成任务。你可以离开,Agent会自己搞定。
用一个生活化的比喻:
- 传统AI = 咨询顾问——只给建议,不动手
- AI Agent = 实习生——你交代任务,他自己想办法完成
AI Agent的核心能力可以归结为三点:
- 感知:理解任务目标,感知当前状态
- 规划:拆解任务,确定执行步骤
- 执行:调用工具,完成具体操作
企业应用现状:哪些场景正在被改变
场景一:智能客服
传统模式:
- 人工客服7×24小时值班,人力成本高
- 标准化问题重复回答,效率低下
- 夜间/节假日响应延迟,客户体验差
AI Agent模式:
python
# 智能客服Agent示例
customer_service_agent = Agent(
name="智能客服",
role="处理客户咨询和投诉",
tools=[
product_knowledge_base, # 产品知识库
order_system, # 订单系统
crm_system # 客户关系管理
],
workflow="""
1. 理解客户问题,判断问题类型
2. 检索知识库,匹配标准解决方案
3. 如需查询订单,调用订单系统
4. 生成个性化回复
5. 如遇到无法解决的问题,转人工并生成交接报告
"""
)
实际效果:
- 7×24小时无间断服务
- 标准化问题100%自动处理
- 复杂问题无缝转人工,客服效率提升3-5倍
场景二:数据处理与分析
传统模式:
- 分析师手动从多个系统提取数据
- 重复性的报表制作占用大量时间
- 数据口径不统一,分析结论常打架
AI Agent模式:
python
# 数据分析Agent示例
data_analyst_agent = Agent(
name="数据分析师",
role="自动完成数据分析任务",
tools=[
database_connector, # 数据库连接器
excel_manipulator, # Excel操作工具
chart_generator, # 图表生成器
report_template # 报告模板库
],
workflow="""
1. 理解数据分析需求
2. 连接数据源,提取原始数据
3. 数据清洗和预处理
4. 执行预定义的分析模型
5. 生成可视化图表
6. 撰写分析结论报告
"""
)
实际效果:
- 报表生成时间从4小时缩短至15分钟
- 数据提取自动化,减少人工操作错误
- 支持实时数据更新,分析时效性大幅提升
场景三:代码开发与测试
传统模式:
- 开发者花费大量时间在重复性代码编写上
- Code Review依赖人工,效率低且容易遗漏
- 测试用例编写耗时,影响交付速度
AI Agent模式:
python
# 代码开发Agent示例
code_developer_agent = Agent(
name="开发助手",
role="辅助代码开发和质量保障",
tools=[
code_repository, # 代码仓库
git_operations, # Git操作
static_analyzer, # 静态代码分析
test_generator # 测试用例生成
],
workflow="""
1. 理解开发任务需求
2. 分析现有代码结构和风格
3. 生成符合项目规范的代码
4. 自动生成单元测试用例
5. 执行代码质量检查
6. 提交代码并创建PR
"""
)
实际效果:
- 重复性代码开发效率提升60%
- 代码审查覆盖率从30%提升至100%
- 测试用例编写时间减少70%
实战案例:三个不同规模企业的落地实践
案例一:电商企业客服智能化
背景:某中型电商平台,日均咨询量5000+,人工客服20人
痛点:
- 客服人员流失率高,培训成本大
- 促销期间咨询量暴增,无法快速扩容
- 退换货处理流程繁琐,客诉率高
解决方案:
部署AI客服Agent,接入商品知识库、订单系统、物流API
关键代码:
python
from agents import Agent, Tool
# 定义工具
product_kb = Tool(
name="商品知识库",
description="查询商品信息、退换货政策",
func=query_product_knowledge
)
order_sys = Tool(
name="订单系统",
description="查询订单状态、修改地址、取消订单",
func=order_system_operations
)
logistics = Tool(
name="物流查询",
description="查询物流进度、快递公司信息",
func=query_logistics
)
# 创建Agent
ecommerce_agent = Agent(
name="电商客服Agent",
tools=[product_kb, order_sys, logistics],
max_iterations=10
)
# 处理客户咨询
result = ecommerce_agent.run("我想查一下订单号A123456的物流情况,同时问一下这个商品怎么退货")
落地效果:
- 60%的咨询完全自动化处理
- 人工客服日均处理量从250降至100
- 客户满意度从72%提升至89%
- 年度人力成本节省约120万元
案例二:制造企业供应链优化
背景:某汽车零部件制造商,供应商200+,日均采购单300+
痛点:
- 供应商交期跟踪依赖人工Excel维护
- 采购员每天花费3小时处理订单状态查询
- 物料短缺预警滞后,影响生产计划
解决方案:
部署供应链监控Agent,对接ERP系统、物流追踪API、供应商门户
关键代码:
python
# 供应链监控Agent
supply_chain_agent = Agent(
name="供应链监控",
role="实时监控供应链状态,提前预警风险",
tools=[
erp_connector, # ERP系统连接
logistics_tracker, # 物流追踪
supplier_portal, # 供应商门户
alert_system # 预警系统
],
workflow="""
1. 每日自动从ERP拉取采购单状态
2. 追踪每笔订单的物流进度
3. 对比供应商承诺交期与实际状态
4. 识别潜在延迟风险
5. 自动生成预警报告,推送给采购员
6. 建议替代供应商或调整生产计划
"""
)
落地效果:
- 物料短缺预警提前7天(原来平均延迟3天才发现)
- 采购员事务性工作时间减少60%
- 年度因物料问题导致的生产损失减少45%
案例三:金融机构合规审计
背景:某城商行,合规部门15人,日均交易50万笔
痛点:
- 交易监控规则更新频繁,维护成本高
- 可疑交易识别依赖固定规则,容易漏检
- 审计报告编写耗时,难以快速响应监管问询
解决方案:
部署智能合规Agent,接入交易系统、风控规则库、监管政策库
关键代码:
python
# 合规审计Agent
compliance_agent = Agent(
name="合规审计Agent",
role="智能识别合规风险,生成审计报告",
tools=[
transaction_system, # 交易系统
risk_rules_engine, # 风控规则引擎
policy_database, # 监管政策库
report_generator # 报告生成器
],
workflow="""
1. 实时监控交易流,提取异常特征
2. 结合风控规则和历史案例综合判断
3. 对可疑交易进行关联分析
4. 生成初步调查结论和处理建议
5. 自动生成监管要求的合规报告
6. 更新风控规则库,持续学习优化
"""
)
落地效果:
- 可疑交易识别率从78%提升至94%
- 审计报告生成时间从5天缩短至4小时
- 监管问询响应时间从72小时缩短至8小时
技术选型指南:如何选择合适的AI Agent框架
主流框架对比
| 框架 | 厂商 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| Claude Code | Anthropic | 代码能力强,企业级支持 | 主要面向开发场景 | 代码开发、自动化测试 |
| GPT Agent | OpenAI | 生态完善,工具丰富 | 成本较高 | 通用场景,企业应用 |
| Qwen Agent | 阿里 | 中文理解强,性价比高 | 生态相对年轻 | 国内企业,中文场景 |
| GLM Agent | 智谱 | 长任务处理能力强 | 文档相对欠缺 | 长流程自动化 |
选型决策树
plaintext
┌─────────────────┐
│ 你的核心场景 │
└────────┬────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ 代码开发 │ │ 客服/文档 │ │ 复杂长流程│
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
▼ ▼ ▼
Claude Code Qwen Agent GLM Agent
GPT Agent GLM Agent Claude Code
成本考量
API调用成本(仅供参考,实际价格请以官方为准):
| 模型 | 输入价格 | 输出价格 | 适用量级 |
|---|---|---|---|
| Claude Sonnet | $3/百万Token | $15/百万Token | 中小规模 |
| GPT-4o | $2.5/百万Token | $10/百万Token | 中等规模 |
| Qwen3.5-Max | ¥15/百万Token | ¥50/百万Token | 大规模 |
| GLM-5 | ¥5/百万Token | ¥15/百万Token | 大规模 |
成本优化建议:
- 对于简单任务,优先使用小模型
- 批量任务采用异步处理,利用低谷折扣
- 设计任务路由,将简单和复杂任务分流
避坑指南:企业落地AI Agent的常见误区
误区一:上来就搞大项目
错误做法:
“我们要用AI重构整个业务流程!”
问题:
- 项目太大,风险不可控
- 失败成本高,影响团队信心
- 难以快速验证价值
正确做法:
从单一高频场景切入,如”自动回复客户物流查询”,验证价值后再扩展。
误区二:忽视人工审核机制
错误做法:
“AI处理就行了,不用人工复核!”
问题:
- AI可能出现”幻觉”,产生错误结论
- 关键决策缺少人工把关,风险累积
- 无法建立持续优化机制
正确做法:
设计”AI处理 + 人工抽检 + 反馈优化”的工作流,在效率和质量间取得平衡。
误区三:工具选型拍脑袋
错误做法:
“某某大厂在用这个框架,我们也用!”
问题:
- 脱离实际场景的需求分析
- 技术选型与团队能力不匹配
- 后续维护困难
正确做法:
基于”场景需求 → 技术评估 → POC验证 → 选型决策”的流程选择工具。
误区四:只看技术指标
错误做法:
“基准测试分数高,就选这个!”
问题:
- 基准测试无法完全反映真实场景表现
- 忽略了部署成本和维护复杂度
- 供应商服务能力难以量化
正确做法:
综合考虑技术能力、成本、服务支持、长期稳定性等多个维度。
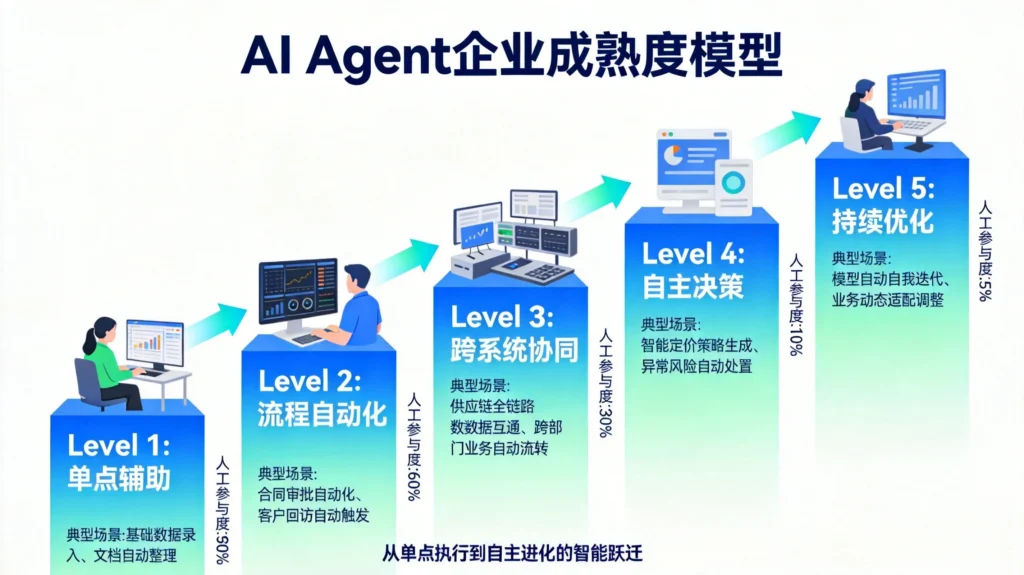
落地路线图:企业AI Agent成熟度模型
Level 1:单点辅助
- AI作为助手,回答问题、生成内容
- 人工审核所有输出
- 典型场景:智能客服(人工复核模式)
Level 2:流程自动化
- AI完成单一完整任务
- 人工抽检关键节点
- 典型场景:自动生成报告、数据清洗
Level 3:跨系统协同
- AI调用多个系统协同工作
- 异常情况转人工处理
- 典型场景:订单处理、供应商管理
Level 4:自主决策
- AI在限定范围内自主决策
- 定期人工审计和规则更新
- 典型场景:智能风控、自动调度
Level 5:持续优化
- AI自主学习,持续优化
- 人工负责战略层面决策
- 典型场景:自适应业务流程
建议:大多数企业从Level 2-3起步,稳扎稳打,逐步提升。
总结
AI Agent正在从概念走向落地,已经在客服、数据处理、代码开发等场景产生了实际价值。
对于希望启动智能化转型的企业,我的建议是:
1.从小处着手
选择单一高频场景作为切入点,快速验证价值,建立团队信心。
2.重视人机协作
AI Agent不是替代人,而是增强人。设计好人机协作的流程,比单纯追求自动化率更重要。
3.持续优化
AI Agent的价值在于学习和进化。建立反馈机制,让Agent越用越聪明。
4.风险管理
对关键决策保持人工把关,对AI输出保持审慎态度。在效率和安全之间找到平衡点。
智能化转型不是一蹴而就的事,但只要方向对了,每一步都是在向正确的方向前进。希望本文提供的案例和方法,能为你的转型之路提供一些参考。
如果你正在考虑引入AI Agent,不妨先从一个小场景开始尝试。实践出真知,只有真正用过,才能理解它的价值所在。