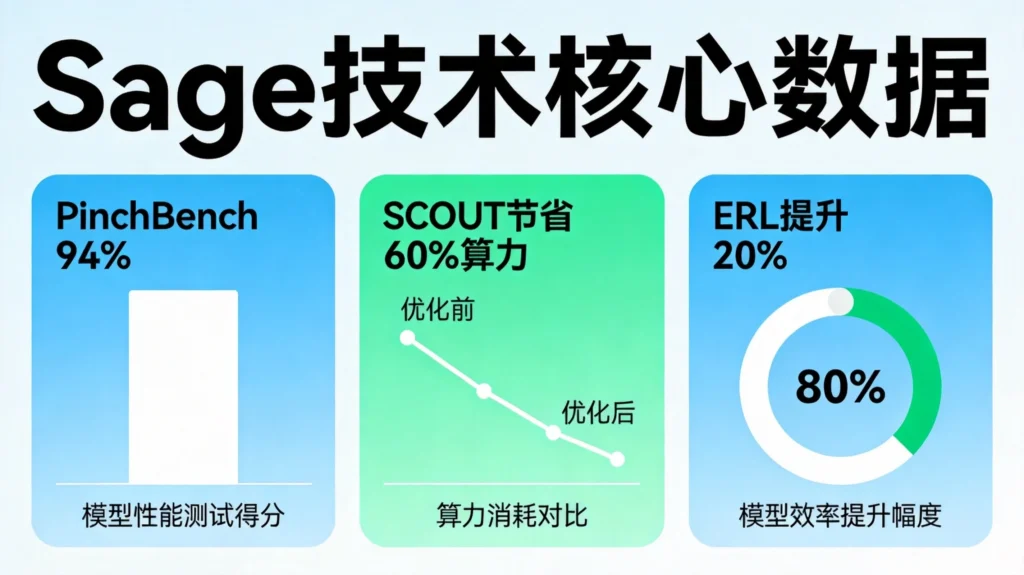
正文
一、开源浪潮:从边缘到主流
曾几何时,大模型领域被视为闭源巨头的专属领地。OpenAI的GPT系列、Google的Gemini系列、Anthropic的Claude系列,凭借强大的技术实力和资源优势,占据了行业领先地位。但这一格局正在被开源力量打破。
2024年被视为开源大模型的元年。Meta的Llama系列首次让中小企业和开发者能够训练自己的大模型。Mistral AI以小规模参数实现强大性能,证明了“小模型也能有大能力”。
2025年开源生态加速成熟。DeepSeek V3以不到600万美元的训练成本,实现了与GPT-4o比肩的性能,震惊业界。开源模型的性能差距与闭源模型迅速缩小。
2026年开源已成燎原之势。进入2026年,国产开源模型集体发力,DeepSeek、Kimi、Qwen等轮番发布重磅更新,开源模型生态呈现百花齐放的局面。
二、主要开源模型最新进展
2.1 DeepSeek系列:极致效率的追求者
DeepSeek系列由深度求索公司推出,以“极致效率”为核心理念。DeepSeek-V4于2026年初发布,在多个基准测试中取得领先成绩。
核心技术特点:
- 混合专家架构(MoE):通过稀疏激活机制,大幅降低计算成本
- FP8混合精度训练:采用创新的低精度训练技术,训练效率提升40%
- 长上下文支持:支持100万token超长上下文处理
性能表现:在MMLU、HumanEval、GSM8K等主流基准测试中,DeepSeek-V4与GPT-4o、Claude 3.5 Sonnet等闭源模型基本持平,部分场景甚至领先。
开放程度:DeepSeek-V4的权重完全开放,支持商业使用,仅需遵守许可协议。这使其成为企业自建AI能力的热门选择。
2.2 Kimi K2.6:超长上下文的先行者
月之暗面旗下的Kimi系列,以超长上下文处理能力著称。K2.6版本于2026年4月发布,是开源社区的里程碑事件。
核心技术特点:
- 200万字无损上下文:业界领先的长文本处理能力
- 优化的注意力机制:通过稀疏注意力降低长文本计算成本
- 增强的中文理解:针对中文语境的专项优化
性能表现:在长文档理解、长代码处理、多文件分析等场景,K2.6展现出明显优势。在开源模型中,K2.6的编程能力(SWE-Bench)处于领先水平。
开源影响:K2.6开源版本在GitHub上线后迅速获得超过5万星,HuggingFace下载量持续攀升,成为开发者社区最受欢迎的开源模型之一。
2.3 Qwen3.6:阿里开源的集大成者
阿里巴巴的通义千问(Qwen)系列是国产开源模型的代表。Qwen3.6于2026年初发布,包含多个规格的模型变体。
核心技术特点:
- 多规格覆盖:从0.5B到72B参数,覆盖从端侧到云端的全场景需求
- 强大的代码能力:编程辅助能力大幅提升,接近GPT-4水平
- 多语言支持:支持超过100种语言的预训练和对话
性能表现:Qwen3.6-72B在多项基准测试中达到GPT-4水平,Qwen3.6-Plus在中文理解能力上更是登顶多个榜单。Qwen系列模型在HuggingFace的下载量累计超过10亿次。
生态建设:阿里云百炼平台为Qwen提供了完整的商业化支持,API调用量持续增长,成为国内企业使用开源模型的主要渠道之一。
2.4 Llama 4:Meta的持续进击
Llama系列是开源大模型的鼻祖,Meta的持续投入使其保持了旺盛的生命力。Llama 4于2026年初发布,延续了Meta在开源领域的领先地位。
核心技术特点:
- 原生多模态:从训练阶段即支持文本、图像、视频的联合处理
- 超大规模:最大版本参数规模达到500B,远超其他开源模型
- MoE架构:采用混合专家架构,在性能和成本间取得平衡
性能表现:Llama 4 MoE在多项基准测试中与GPT-4o基本持平,代码能力显著提升,多模态理解能力更是开源领域的标杆。
社区影响:Llama系列在开源社区的影响力无可比拟。Llama 4发布后,HuggingFace、GitHub等平台的模型下载量、代码引用量持续攀升,衍生模型数量已超过10万。
三、开源生态的繁荣密码
开源大模型之所以能够快速崛起,形成了与闭源巨头分庭抗礼的局面,有其深层逻辑。
技术民主化的内在需求。AI技术不应被少数巨头垄断,中小企业、研究机构、独立开发者都有使用大模型的需求。开源模型满足了这一需求,让更多人能够参与AI革命。
开源社区的协作力量。全球开发者社区贡献的代码、数据、经验,持续推动开源模型的优化和进化。这种集体智慧的力量,是闭源公司内部团队难以比拟的。
商业模式的创新。开源模型不等于不赚钱。模型开源、API收费;基础模型免费、高级功能付费;社区版免费、企业版付费……多元化的商业模式,让开源模型既能保持开放性,又能实现商业价值。
信任与可控性的诉求。使用闭源模型,企业需要将数据发送给第三方平台,存在数据安全和隐私风险。开源模型可以私有化部署,满足了部分企业对数据控制的需求。
四、开源与闭源:路线之争的本质
开源与闭源的竞争,表面上是技术路线的差异,深层是商业逻辑和价值观的碰撞。
闭源阵营的逻辑:高投入需要高回报,知识产权保护是创新的动力。开放源代码会削弱竞争优势,不利于持续投入。
开源阵营的逻辑:开放促进创新,生态繁荣最终惠及所有人。闭源垄断阻碍技术进步,不利于产业健康发展。
现实的选择:两种路线并非非此即彼,而是各有适用场景。
- 对于需要快速上线、资金充裕的企业,闭源模型提供了开箱即用的便利
- 对于需要定制化、有数据安全要求的企业,开源模型提供了灵活部署的可能
- 对于学术界和研究机构,开源模型是开展研究的基础设施
- 对于个人开发者和学生,开源模型是学习和实践的最佳平台
五、开源生态面临的挑战
尽管开源大模型发展迅猛,但仍面临若干挑战。
计算资源门槛:训练大模型的算力需求依然惊人,普通机构难以承担。开源社区需要探索新的训练模式,如分布式协作、算力众筹等。
模型安全风险:开源意味着模型能力可能被滥用。Agent能力、自动工具调用等功能的开放,增加了安全风险。如何在开放与安全之间取得平衡,是开源社区需要面对的问题。
商业可持续性:开源不等于免费,企业需要找到健康的商业模式。如何在开源开放与商业变现之间找到平衡点,关系到开源项目的长期发展。
生态碎片化:开源社区的贡献是分散的,可能导致标准不统一、生态碎片化。建立和维护开放标准,是保持生态健康的关键。
六、未来展望
短期看,开源与闭源的差距将继续缩小。随着训练技术的进步和算力成本的下降,更多机构将有能力训练自己的大模型,开源模型的性能和覆盖范围将进一步提升。
中期看,开源与闭源将呈现差异化竞争格局。闭源模型聚焦高端市场,追求极致性能;开源模型覆盖中低端市场,追求性价比和灵活性。两者在不同场景各擅胜场。
长期看,开源AI有望成为AGI时代的基础设施。类比Linux之于操作系统、开源软件之于企业IT,开源AI可能成为支撑整个产业生态的底层力量。
七、结语
开源大模型的崛起,是AI产业发展史上的重要里程碑。它打破了闭源巨头的垄断,降低了AI技术的使用门槛,推动了创新的加速涌现。
DeepSeek、Kimi K2.6、Qwen3.6、Llama 4……这些开源模型的背后,是无数研究者和开发者的智慧结晶。它们不仅是技术进步的成果,更是开源精神的生动体现。
站在2026年的节点回望,我们有理由相信:开源AI的未来,值得期待。