2026年5月20日,杭州阿里云峰会现场,当通义千问Qwen3.7系列正式亮相时,掌声经久不息。仅仅一天前,Google I/O 2026刚刚落下帷幕,Gemini 3.5系列高调登场;仅仅两天后,阿里选择在同一时间窗口亮出自己的王牌,这背后的竞争意图不言自明。
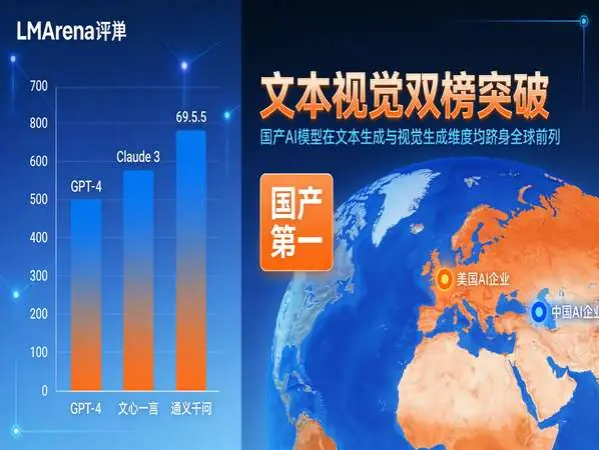
而Qwen3.7交出的答卷也确实令人眼前一亮:在全球最具公信力的AI模型评测平台LMArena上,Qwen3.7-Max-Preview在文本领域一举冲至全球第13位,阿里巴巴实验室综合排名攀升至全球第6——成为当前排行榜上当之无愧的国产第一。在视觉领域,Qwen3.7-Plus-Preview同样表现不俗,以第16名的成绩将阿里巴巴实验室送上视觉榜国产榜首的位置。
这不是一次普通的版本迭代。从Qwen1.0到Qwen3.7,阿里走了三年。这三年里,中国大模型行业经历了从追赶到并跑、从模仿到创新的深刻蜕变。而Qwen3.7,或许正是这场蜕变的标志性注脚。
从追赶到领跑:国产大模型的三年进化论
时间拨回2023年,国产大模型刚刚起步。彼时的行业共识是:中国AI企业与OpenAI、Google等国际巨头之间存在明显差距,追随与学习是唯一可行的路径。但没人想到,这个差距会以如此快的速度被缩小。
通义千问的成长轨迹就是最好的例证。2023年4月,Qwen-7B首次亮相,参数规模70亿;2024年,Qwen2.0系列发布,在多项评测中开始与国际主流模型掰手腕;2025年,Qwen3.0系列实现质的飞跃,部分任务表现已逼近GPT-4;而今天,Qwen3.7以文本榜第13名、视觉榜第16名的成绩,正式宣告国产大模型进入全球第一梯队。
这种进化速度在AI领域是罕见的。业内人士分析,这背后是三重力量的叠加:首先是阿里巴巴持续加码的研发投入,仅未来三年规划资本支出就超过3800亿元,主要用于AI基础设施与算力建设;其次是中文互联网海量高质量数据的天然优势,让通义千问在中文理解任务上具有先天基因;第三则是整个国产AI生态的协同进化,从芯片层的华为昇腾到框架层的各类优化工具,产业链上下游的紧密配合为模型迭代提供了坚实底座。
Qwen3.7核心技术解析:它到底强在哪里?
虽然阿里在发布会上并未公布Qwen3.7的具体参数规模和技术细节,但结合多方信息,我们可以勾勒出这款新模型的几大核心能力。
多模态融合能力的突破是Qwen3.7最引人注目的升级方向。从命名来看,Qwen3.7-Max-Preview和Qwen3.7-Plus-Preview分别对应文本和视觉能力的强化版本,而Plus版本在视觉榜上的出色表现意味着其多模态理解能力已达到业界领先水准。这意味着Qwen3.7不仅能”读懂”文字,还能精准理解图片内容、图表信息乃至视频帧,在需要跨模态推理的任务中表现更加游刃有余。
长上下文处理能力的增强同样值得关注。当前大模型竞争的一个关键维度就是上下文窗口大小,更长的上下文意味着模型能够处理更复杂的任务,比如阅读整本书籍、分析大型代码库、进行多轮复杂对话等。从此前Qwen系列的演进路径推断,Qwen3.7的上下文窗口大概率已突破百万token级别,这使其在处理长文档、长对话等场景时具有显著优势。
推理效率的优化则是另一个不可忽视的亮点。在当前”算力即成本”的行业背景下,模型的推理效率直接决定了其商业化可行性。Qwen3.7在保持高性能的同时大幅提升了推理速度,降低了部署门槛,这对于阿里云面向企业客户的商业化推广至关重要。
中美AI竞争的新格局:国产力量正在改写规则
Qwen3.7的发布时机颇为微妙。就在前一天,Google I/O 2026刚刚展示了Gemini 3.5系列的多项升级,包括搜索框25年来最大改版、Gemini Spark智能体登场、以及AI Ultra订阅降价等一系列动作。而在同一时间窗口,OpenAI也在推进GPT-5.5系列的更新,并透露了冲刺2026年底IPO的计划。
三家巨头几乎在同一时间段密集发布或更新重磅产品,这种”正面对决”的场面在AI行业并不常见。但仔细观察会发现,中美两国企业的竞争策略已呈现出明显分化:美国企业更注重大一统的平台生态建设,从搜索到办公到硬件全面覆盖;而中国企业则更聚焦于垂直场景的深耕和商业化落地,在特定领域建立差异化优势。
这种分化在数据上也有体现。据AItop100最新统计,中国大模型周调用量已达7.693万亿Token,连续三周超越美国的4.24万亿Token,是美国的1.81倍。榜首腾讯混元Hy3 Preview周调用量高达2.66万亿Token,即便转向收费模式后仍稳居第一,说明中国用户对AI工具的实际使用热情和付费意愿都在持续升温。
在这个大背景下,Qwen3.7的发布不仅是阿里一家的产品升级,更是国产大模型在全球竞争中的一次集体冲锋。当中国AI企业开始在排行榜上占据越来越靠前的位置,当国产模型的商业化落地越来越成熟,整个行业的游戏规则正在被重新书写。
商业化路径:阿里云的AI变现棋局
对于阿里巴巴而言,Qwen3.7的发布绝非单纯的”秀肌肉”,而是其AI商业化战略的关键落子。
阿里巴巴最新财报显示,公司对未来三年的资本支出规划超过3800亿元,主要投向AI基础设施和算力建设。这笔巨额投入背后,是阿里云对AI时代商业机会的精准判断。随着Qwen系列模型能力的持续提升,其在阿里云平台上的调用量和收入贡献也在稳步增长。
从商业模式来看,阿里云的AI变现路径已相当清晰:基础层面,Qwen系列通过API调用按token计费,这是最直接的收入来源;中间层面,阿里云提供模型微调、部署托管等增值服务,面向企业客户收取更高客单价;顶层层面,结合阿里生态内的电商、物流、金融等场景,将AI能力内化为业务效率的提升工具。
Qwen3.7的发布恰逢腾讯云宣布Hy3 Preview和DeepSeek-V4-Pro将于5月27日结束免费公测,转为正式商用。这意味着国内大模型服务正从”烧钱换用户”的拉新阶段全面转向”商业化兑现”的新阶段。在这场行业变局中,拥有更强模型能力、更多企业客户、更完善商业闭环的企业将占据先机。
展望未来:Qwen3.7将如何影响行业走向?
Qwen3.7的发布对行业的影响是多层面的。
对开发者而言,Qwen3.7登顶国产第一意味着又多了一个强有力的模型选择。基于通义千问的开发生态已经相当成熟,Hugging Face、GitHub上有大量基于Qwen系列的开源项目和工具,开发者可以快速将Qwen3.7集成到自己的应用中。
对企业客户而言,Qwen3.7的能力提升为更复杂的AI应用场景提供了可能。无论是智能客服、内容审核、数据分析还是知识管理,更强的模型能力都意味着更高的任务完成率和更好的用户体验。
对竞争格局而言,Qwen3.7的成功发布将进一步加剧国产大模型之间的竞争。在文心一言、Kimi、智谱清言、腾讯混元等对手的夹击下,通义千问能否守住国产第一的位置,还需要时间来检验。但可以确定的是,这种良性竞争将推动整个国产AI行业持续进步。
结语
回望通义千问的三年进化历程,从最初70亿参数的小模型,到今天文本视觉双榜登顶的旗舰系列,阿里用实际行动证明了中国AI企业的创新潜力。Qwen3.7的发布,不仅是一款新产品的亮相,更是国产大模型在全球AI竞争版图上刻下的一个新坐标。
当然,排名只是一个维度,真正的较量还在于技术创新的深度、商业落地的广度、以及产业生态的厚度。在这个日新月异的行业里,没有谁能永远站在榜首。但有一点是确定的:只要持续创新、持续进化,机会就永远在前方等着。
对于中国AI行业而言,Qwen3.7或许只是一个新起点。下一个三年,我们期待看到更多国产力量的崛起,见证中国AI从追赶者成长为真正的领跑者。
术语表
LMArena:全球知名AI模型评测平台,通过众包测试方式对各大语言模型进行能力评估,是目前最具公信力的AI模型排行榜之一。
多模态(Multimodal) :指能够处理和理解多种类型数据(如文本、图像、音频、视频)的人工智能模型能力。
API调用:应用程序编程接口调用,指开发者通过程序接口使用云端AI模型服务的方式。
Token:语言模型处理的最小单位,一次API调用消耗的token数量决定计费金额。