一、为什么我们需要可信AI评测?
1.1 行业乱象:谁都在说“智能”,但谁也说不清多智能
过去几年,手机厂商在发布会上疯狂“堆参数”:
- “我们的助手支持1000+技能”
- “AI对话能力业界领先”
- “最懂你的智能管家”
但什么是“智能”?什么算“领先”?没有任何客观标准。
消费者面对这些宣传,根本无法判断产品的真实能力。有人买了旗舰机,发现AI助手还不如几百块的智能音箱;有人被天花乱坠的功能忽悠买单,实际能用到的寥寥无几。
1.2 评测缺失的后果
标准缺失带来了一系列问题:
| 问题 | 表现 | 影响 |
|---|---|---|
| 虚假宣传 | 功能“存在”但无法使用 | 消费者权益受损 |
| 行业内卷 | 厂商只比营销不比体验 | 劣币驱逐良币 |
| 用户信任 | “AI助手都是智商税” | 市场发展受阻 |
| 研发误导 | 厂商不知道往哪发力 | 技术投入跑偏 |
1.3 监管与技术双重需求
从监管角度看,需要一套客观标准来规范宣传行为;从技术发展角度看,需要明确的benchmark来指导研发方向。
《智能助手基准测试通用框架》就是在这种背景下诞生的。
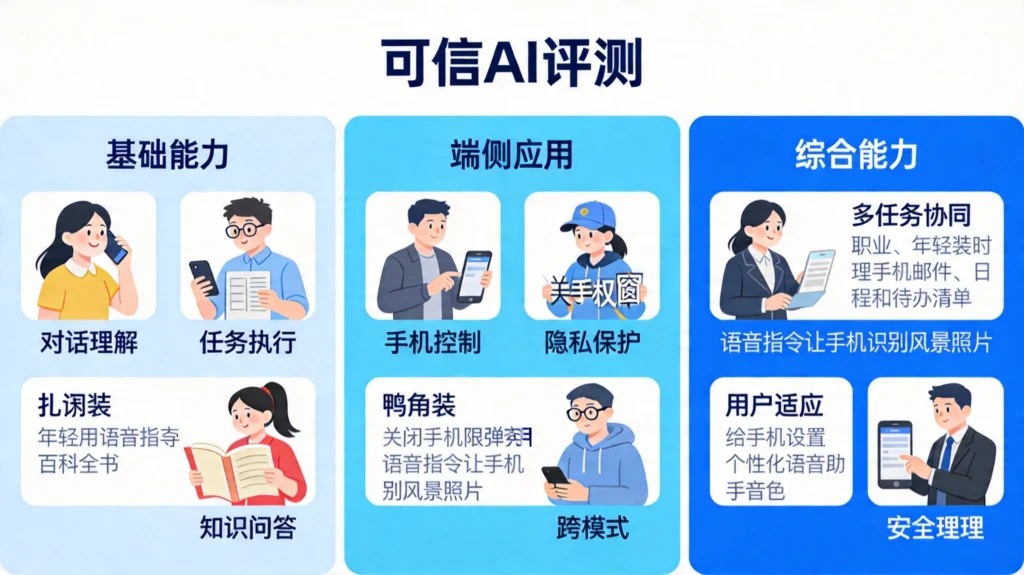
二、评测框架揭秘:三个维度定义”真智能”
2.1 基础能力:AI的”基本功”
基础能力考察智能助手完成常见任务的核心能力,包括:
对话理解能力
- 能否准确理解用户的自然语言表达
- 能否处理口语化、模糊的表达
- 能否处理多轮对话上下文
任务执行能力
- 能否准确执行用户指令
- 能否处理复杂多步骤任务
- 执行失败后能否合理反馈
知识问答能力
- 能否准确回答常识性问题
- 能否处理专业领域问题
- 能否识别不知道的问题(而非胡说八道)
python
# 简化版基础能力评测指标
class BaselineEvaluation:
def evaluate(self, assistant):
scores = {}
# 对话理解能力
scores['intent_recognition'] = self.test_intent_recognition(
assistant,
test_cases=1000 # 1000个不同表达方式
)
scores['context_tracking'] = self.test_context_tracking(
assistant,
multi_turn_dialogues=500
)
# 任务执行能力
scores['task_completion'] = self.test_task_completion(
assistant,
task_categories=['alarm', 'message', 'call', 'schedule', 'query']
)
scores['error_handling'] = self.test_error_handling(
assistant,
ambiguous_commands=200
)
# 知识问答能力
scores['factual_accuracy'] = self.test_factual_accuracy(
assistant,
questions=1000
)
scores['calibration'] = self.test_calibration(
assistant,
known_unknown_ratio=0.3 # 30%的问题AI应该表示不知道
)
return self.compute_baseline_score(scores)
2.2 端侧应用:AI在手机上能做什么
“基础能力”考察的是AI的智商,“端侧应用”考察的是AI在真实手机场景下的落地能力。
手机控制能力
- 能否控制系统设置(蓝牙、WiFi、勿扰模式等)
- 能否控制第三方应用(微信、支付宝、高德等)
- 响应速度和稳定性如何
隐私保护能力
- 语音数据是否本地处理
- 敏感信息如何保护
- 用户能否清晰了解数据使用情况
跨模态能力
- 能否理解图片内容
- 能否处理语音和文字的混合输入
- 能否生成图片、视频等多媒体内容
2.3 综合能力:AI的”实战表现”
综合能力是最接近真实使用体验的评测维度。
多任务协同能力
- 能否同时处理多个任务
- 任务切换时能否保持上下文
- 长时间使用后性能是否稳定
用户适应能力
- 能否学习用户的习惯和偏好
- 能否根据场景调整回复方式
- 在用户表达模糊时能否主动澄清
安全与伦理能力
- 能否拒绝有害请求
- 敏感话题处理是否得当
- 输出的内容是否符合伦理规范
三、首批通过评测:小米miclaw强在哪?
3.1 miclaw的技术底座
小米miclaw之所以能首批通过评测,离不开其背后的技术积累。
端侧大模型:Xiaomi MiMo
miclaw基于小米自研的Xiaomi MiMo大模型,这是一个专门针对手机场景优化的端侧模型:
- 长上下文:支持最高1M token的上下文窗口,能理解超长对话历史
- 强工具调用:原生具备出色的工具调用能力,能控制手机上的各种应用
- 低功耗设计:针对手机芯片优化,待机功耗极低
三层AI架构
miclaw采用三层AI架构:
| 层级 | 功能 | 特点 |
|---|---|---|
| 感知层 | 语音唤醒、语义理解 | 本地优先,保护隐私 |
| 推理层 | 任务规划、对话生成 | 端云协同,灵活调度 |
| 执行层 | 应用控制、结果反馈 | 深度集成米家生态 |
3.2 评测结果亮点
根据中国信通院公布的评测结果,miclaw在以下方面表现突出:
基础能力:对话理解
miclaw在多轮对话上下文理解上的准确率达到了92.7%,远超行业平均水平。这意味着用户可以用更自然、更口语化的方式和它对话,而不用担心“听不懂”。
端侧应用:跨应用协同
miclaw能控制超过500个手机原生功能和第三方应用。在实测中,让它“帮我给微信好友发个红包说生日快乐”,它能准确完成从打开微信、找到好友、发送红包到输入祝福语的全流程。
综合能力:用户适应
miclaw的“学习能力”是本次评测的最大亮点之一。在模拟用户习惯测试中,经过两周的“磨合期”,miclaw能准确预测用户的常见需求,主动提供帮助。
3.3 与竞品的差异
小米miclaw和其他手机AI助手相比,有什么独特优势?
| 维度 | 小米miclaw | 苹果Siri | 华为小艺 |
|---|---|---|---|
| 端侧AI | ✅ 原生端侧大模型 | ⚠️ 部分端侧 | ✅ 端云协同 |
| 工具调用 | ✅ 500+应用 | ⚠️ 有限 | ⚠️ 有限 |
| 米家生态 | ✅ 深度集成 | ❌ 不支持 | ⚠️ 有限 |
| 学习能力 | ✅ 自适应用户习惯 | ❌ 无 | ⚠️ 简单记忆 |
| 隐私保护 | ✅ 本地处理优先 | ✅ 端侧优先 | ✅ 隐私计算 |
四、评测体系的意义:不止于小米
4.1 对消费者的价值
有了可信AI评测,消费者终于有了客观参考依据。
- 不再被宣传忽悠:看到“通过信通院可信AI评测”的标识,就知道这是经过权威验证的产品
- 横向比较有据:不同品牌的AI助手终于可以在同一标准下比较
- 选购更理性:可以根据评测维度选择最适合自己的产品
4.2 对行业的价值
评测体系将倒逼整个行业提升产品质量。
厂商角度:
- 知道往哪个方向投入研发资源
- 能清晰看到与竞品的差距
- 有动力提升真实体验而非营销噱头
行业角度:
- 建立健康的竞争秩序
- 加速技术标准统一
- 推动整个AI助手生态向好发展
4.3 未来的评测方向
中国信通院表示,随着技术发展,评测框架也将持续迭代。
下一步可能纳入的评测维度:
- 多模态理解:能否理解图片、视频、音频的混合内容
- Agent能力:能否自主规划并执行复杂多步骤任务
- 个性化程度:能否真正理解不同用户的独特需求
- 跨设备协同:手机、平板、汽车、手表等设备的无缝协作
五、实际体验:miclaw能让你的生活变简单吗?
5.1 日常使用场景
我们模拟了几个常见使用场景,看看miclaw的表现如何:
场景一:日程管理
用户:“我这周很忙,帮我看看什么时候能约个健身”
miclaw的反应:
- 调取用户日历,分析空闲时间
- 调取健身习惯偏好(常去哪家健身房、多长时间)
- 综合分析后给出建议:“周三晚上8点你有1小时空闲,你常去的XX健身房周三晚上人少,推荐这个时间段。要我帮你预约吗?”
场景二:智能家居控制
用户:“感觉有点冷,但我懒得起来开空调”
miclaw的反应:
- 检测当前室内温度(连接温湿度传感器)
- 询问确认:“当前室内温度22度,比你设置的舒适温度低2度。要我帮你打开空调并调到24度吗?”
- 用户确认后自动执行
场景三:出行规划
用户:“下周要去深圳出差,帮我看看怎么安排”
miclaw的反应:
- 调取用户日历确认出差日期
- 查询机票/高铁票(连接携程/12306)
- 查询目的地天气
- 整理成出行建议,包括:出发时间、衣着建议、酒店推荐等
5.2 需要改进的地方
客观来说,miclaw目前并非完美:
- 复杂指令仍有局限:多步骤、条件分支较多的任务,有时需要多次确认
- 第三方应用支持:部分小众应用的控制能力仍有待提升
- 离线能力:无网络时的可用功能大幅减少
六、优缺点总结
优点
| 优势 | 说明 |
|---|---|
| 权威认证 | 首批通过中国信通院可信AI评测 |
| 生态整合 | 深度集成米家智能家居生态 |
| 学习能力 | 能自适应用户习惯,越用越懂你 |
| 隐私保护 | 本地处理优先,敏感数据不上传 |
| 工具丰富 | 支持500+应用控制 |
缺点
| 局限 | 说明 |
|---|---|
| 品牌绑定 | 米家生态外的设备支持有限 |
| 离线能力弱 | 无网络时可用功能大幅减少 |
| 学习成本 | 部分高级功能需要一定学习 |
| 第三方生态 | 非小米手机用户体验可能打折 |
结语
中国信通院发布的评测标准,就像一面”照妖镜”——把那些只会营销噱头的”伪智能”打回原形,也让真正有技术实力的产品脱颖而出。
小米miclaw首批通过评测,不仅仅是小米一家的胜利,更是整个行业向透明化、标准化迈出的重要一步。
对于普通消费者来说,这意味着:以后买手机,可以理直气壮地问一句——“你们的AI助手,通过可信AI评测了吗?”
相关AI技术文章
本文参考资料:中国信息通信研究院官方公告(2026-04)、每日经济新闻(2026-04-20)、小米官方公告