引言:国产AI的”超大杯”时刻
2026年4月,中国AI圈迎来一场静默却深刻的变革。
继4月2日发布Qwen3.6-Plus后,阿里通义千问团队于4月20日正式推出Qwen3.6-Max-Preview预览版,在权威评测平台Artificial Analysis上登顶国产大模型综合性能榜首,全面超越GLM5.1、MiniMax-M2.7等竞品。
而早在4月16日,开源社区已炸锅——Qwen3.6-35B-A3B以”350亿总参数、仅激活30亿”的MoE(混合专家)架构横空出世,成为全球开发者争相部署的轻量级新标杆。
这一系列动作,被业内称为”Qwen3.6超大杯三连发“——从闭源旗舰到开源利器,从通用对话到专业编程,阿里正用一套组合拳,重新定义大模型的价值边界。
笔者注意到,这场发布背后最核心的突破,并非参数规模的堆砌,而是**”Agentic Coding”(智能体编程)能力**的质变——Qwen3.6不再只是”能回答问题”,而是能”交付可运行的产品”。
这对国产AI而言,是一次从技术秀场到工程能力的跨越,也是国产大模型真正走向产业化落地的标志。
一、技术底座:MoE架构如何实现”以小博大”
要理解Qwen3.6的技术突破,首先要理解其核心架构——稀疏混合专家(Mixture of Experts,MoE)。
1.1 MoE架构的工作原理
传统大模型在处理每个输入时,都会激活全部参数进行计算。以一个700亿参数模型为例,处理一个简单的”今天天气如何”问题,需要动用全部700亿参数,既浪费算力,又影响效率。
MoE架构的核心思想是”分而治之”:
将模型划分为多个”专家网络”(Experts),每个专家擅长处理不同类型的任务。在处理输入时,一个**门控网络(Gating Network)**会分析输入内容,动态决定应该激活哪些专家,让最合适的专家处理最擅长的任务。
Qwen3.6-35B-A3B的技术规格:
- 总参数:350亿参数,保障知识的广度和深度
- 激活参数:仅30亿参数,大幅降低算力消耗
- 专家数量:8个专家网络,并行处理不同任务
- 路由策略:智能动态路由,根据内容匹配最佳专家
这种设计的精妙之处在于:模型的知识容量没有缩水(350亿参数),但计算成本却大幅降低(仅激活30亿参数)。就像一个团队有100名各领域的专家,但处理每个问题时只召集最相关的3-5名专家参与,既保证了决策质量,又降低了沟通成本。
1.2 性能与效率的双重优化
MoE架构带来的效率提升是显著的:
显存占用降低40%:因为每次推理只需将30亿参数加载到显存中,相比同参数量的稠密模型,显存需求大幅减少。
推理速度提升1.8倍:计算量减少,响应速度自然提升,用户体验更加流畅。
成本直接砍半:算力消耗降低50%,API调用成本同步下降,商业化门槛大幅降低。
这对开发者的意义是:以前跑一个30B模型需要8卡A100,现在一张RTX 4090就能流畅运行Qwen3.6-35B,效果还不输。
1.3 与传统架构的对比
| 架构类型 | 代表模型 | 总参数量 | 激活参数 | 显存需求 | 推理速度 |
|---|
| 稠密架构 | GPT-3 | 175B | 175B | ~350GB | 基准 |
| 稠密架构 | LLaMA 3.1 | 70B | 70B | ~140GB | 0.4x |
| MoE架构 | Qwen3.6-35B-A3B | 350B | 30B | ~60GB | 1.8x |
从这个对比可以看出,MoE架构是实现”大知识、小计算”的关键技术路线,也是2026年大模型发展的主流方向。
二、核心突破:智能体编程的质变
如果说MoE架构是Qwen3.6的”发动机”,那么Agentic Coding(智能体编程)能力就是它的”方向盘”。
2.1 从”辅助工具”到”执行体”
过去一年,大模型在编程领域的表现一直被视为”辅助工具”——能生成代码片段,能提供编程建议,但遇到复杂的软件工程项目,往往力不从心。
Qwen3.6的突破在于:它不再只是”写代码”,而是能”交付产品”。
在权威编程评测中的表现:
- SWE-bench(真实软件工程基准):Qwen3.6-Plus表现超越参数量2-3倍的国产模型,甚至逼近Claude Opus系列
- Terminal-Bench 2.0(终端编程测试):在复杂命令行任务中表现优异
- NL2Repo(自然语言生成完整代码库):能根据自然语言描述生成完整的项目结构
这意味着什么?
它不仅能写代码,还能理解整个项目结构、自动调试、运行测试、修复漏洞,直至交付可运行的软件产品。
一位前端工程师在实测后分享了他的体验:”我让Qwen3.6根据一句’做一个类似Notion的笔记应用’,自动生成了完整的React+Node.js全栈项目,包含用户登录、富文本编辑、云端同步——只用了8分钟。”
2.2 编程能力的深层逻辑
Qwen3.6之所以能在编程领域实现突破,源于阿里团队在三个层面的优化:
1. 代码理解能力的提升
- 能够理解多文件项目的整体架构
- 能够追踪变量在不同文件间的传递和变化
- 能够理解代码的上下文和依赖关系
2. 任务规划的优化
- 能将复杂需求拆解为可执行的子任务
- 能够规划任务执行顺序和依赖关系
- 能够处理任务间的并行和串行关系
3. 工具调用的增强
- 能够调用编译器、解释器、测试框架等开发工具
- 能够读写文件系统,操作项目代码
- 能够执行命令并根据结果调整策略
这三点组合起来,构成了”智能体编程”的基础能力——像人一样思考,像机器一样执行。
2.3 与竞品的横向对比
在编程能力维度,Qwen3.6已展现出与全球顶级模型掰手腕的实力:
| 能力维度 | Qwen3.6-Plus | Claude Opus 4.6 | GPT-5.2 |
|---|
| 代码生成 | ★★★★★ | ★★★★★ | ★★★★★ |
| 代码修复 | ★★★★☆ | ★★★★★ | ★★★★☆ |
| 架构设计 | ★★★★☆ | ★★★★☆ | ★★★★★ |
| 多语言支持 | ★★★★★ | ★★★★☆ | ★★★★☆ |
| 中文场景 | ★★★★★ | ★★★☆☆ | ★★★☆☆ |
从对比可以看出,Qwen3.6在中文场景和中文代码(如小程序、Web开发)方面有明显优势,而在复杂架构设计方面与顶级模型仍有差距,但差距正在缩小。
三、万亿参数旗舰:Qwen3.6-Max的技术解析
除了开源的35B版本,阿里还发布了闭源旗舰Qwen3.6-Max-Preview,采用万亿参数MoE架构,是目前国产综合性能最强的闭源大模型。
3.1 核心技术规格
Qwen3.6-Max技术规格:
- 总参数:万亿级别(约1.2万亿)
- 激活参数:约320-370亿
- 上下文窗口:128K Token
- 多模态能力:原生支持文本、图像、音频、视频
- 编程能力:SWE-bench Verified得分83.7%,超越GPT-5.2
3.2 万亿参数的工程挑战
训练和部署万亿参数模型,面临的工程挑战是巨大的:
算力需求:训练万亿参数模型需要数万张GPU,耗电量惊人。阿里通过与华为昇腾的合作,实现了基于昇腾950PR芯片的训练和推理,大幅降低了算力成本。
分布式训练:将万亿参数拆分到数千张GPU上,需要精细的通信优化和负载均衡策略。阿里在MoE通信、梯度同步等关键环节进行了深度优化。
推理优化:在保持模型能力的同时实现高效推理,需要量化、蒸馏、推理引擎优化等一系列技术。Qwen3.6-Max支持INT8量化,单卡即可运行优化后的推理。
稳定性保障:长时间训练大规模模型,硬件故障是常态。阿里建立了完善的故障检测和恢复机制,保障训练稳定进行。
3.3 性能表现与行业地位
在权威评测平台Artificial Analysis的综合排名中:
- 国产模型排名:Qwen3.6-Max位列第一
- 全球模型排名:超越GLM5.1、MiniMax-M2.7等竞品,逼近GPT-5.2、Claude Opus 4.6
阿里云CTO周靖人表示:”Qwen3.6-Max的目标是成为企业级AI的核心底座,在复杂推理、代码生成、多模态理解等场景提供顶级能力。”
四、国产算力的破局:全栈昇腾适配
Qwen3.6的发布,还有一个容易被忽视但意义深远的突破——全栈昇腾适配。
4.1 为什么要做昇腾适配?
长期以来,国产大模型的训练和推理都依赖英伟达GPU。从CUDA生态到cuDNN库,从TensorRT到vLLM,整个AI基础设施都是为英伟达打造的。
这种依赖带来两个问题:
- 成本高昂:英伟达高端GPU价格昂贵,且受出口管制影响
- 供应链风险:在当前国际形势下,过度依赖单一供应商存在风险
华为昇腾芯片是目前国内最成熟的AI算力解决方案,但在生态适配方面仍面临挑战。
4.2 Qwen3.6的昇腾适配工作
阿里在Qwen3.6的研发过程中,投入了大量资源进行昇腾适配:
训练层面:
- 完成从CUDA到CANN(华为计算架构)的完整迁移
- 优化昇腾芯片上的分布式训练性能
- 解决了大量底层算子兼容性问题
推理层面:
- 昇腾、vLLM等主流推理框架已第一时间完成适配
- 开发者只需一行命令即可在昇腾上部署Qwen3.6
- 性能表现与英伟达生态基本持平
工具链:
- 提供完整的昇腾开发工具链
- 支持主流AI框架(PyTorch、MindSpore等)
- 配套详细的部署文档和最佳实践
4.3 意义:国产AI生态的里程碑
Qwen3.6全栈昇腾适配的意义,远不止于”又多了一个可用选项”。
它标志着:
- 国产大模型可以在国产算力上运行:打破英伟达垄断,降低AI应用门槛
- 国产AI生态走向成熟:从芯片到模型到应用,完整的国产链条已打通
- AI产业自主可控:在极端情况下,国产AI仍能正常运转
正如一位行业观察者所言:”DeepSeek V4和Qwen3.6的昇腾适配,让国产AI终于有了’中国芯+中国脑’的闭环。”
五、生态布局:从模型到平台的完整闭环
Qwen3.6的发布,不只是发布一个模型,而是阿里云AI战略的重要一步。
5.1 百炼平台:企业级AI开发底座
Qwen3.6全系列已接入阿里云百炼平台,提供:
- API调用:按Token计费,支持高并发
- 模型微调:基于Qwen3.6进行企业专属模型训练
- 智能体开发:提供Agent开发框架和工具链
- 行业解决方案:覆盖电商、金融、制造等垂直场景
5.2 通义App:面向普通用户的AI助手
Qwen3.6的核心能力也通过通义App开放给普通用户:
- 多模态交互:支持文字、图像、语音多种输入
- 智能体能力:可以调用外部工具,执行复杂任务
- 知识助手:整合阿里生态的电商、旅行等服务能力
5.3 钉钉集成:企业协同的AI升级
Qwen3.6已深度集成到钉钉生态中:
- 智能客服:基于Qwen3.6的对话式客服机器人
- 文档助手:智能撰写、总结、翻译文档
- 会议纪要:自动生成会议摘要和待办事项
- BI分析:用自然语言查询数据,生成分析报告
六、开发者指南:如何用好Qwen3.6
6.1 开源版本部署
Qwen3.6-35B-A3B已完全开源,支持本地部署:
bash
# 使用vLLM部署
vllm serve Qwen/Qwen3.6-35B-A3B \
--tensor-parallel-size 2 \
--trust-remote-code
# 使用ModelScope
from modelscope import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3.6-35B-A3B")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3.6-35B-A3B")
硬件需求:
- 单卡部署:RTX 4090(24GB显存)或昇腾910B
- 双卡部署:两张RTX 4090,体验更流畅
- 推荐配置:8卡A100或昇腾集群,适合企业级应用
6.2 API调用
python
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen-max",
messages=[
{"role": "system", "content": "你是Qwen,一个AI助手。"},
{"role": "user", "content": "请用Python写一个快速排序算法"}
]
)
print(response.choices[0].message.content)
6.3 智能体开发
python
from qwen_agent import Agent
# 创建智能体
agent = Agent(
model="qwen-max",
tools=["code_interpreter", "web_search", "file_system"]
)
# 定义任务
task = "分析当前AI行业的发展趋势,并生成一份报告"
# 执行任务
result = agent.run(task)
print(result)
七、影响分析:国产AI的范式转移
Qwen3.6的发布,标志着国产AI发展范式的根本转变。
7.1 从”能聊天”到”能干活”
过去一年,国产大模型的竞争焦点是”对话能力”——谁的回答更流畅、更有趣、更像人。
Qwen3.6将竞争焦点转向**”执行能力”**——谁能真正解决问题、完成任务、交付价值。
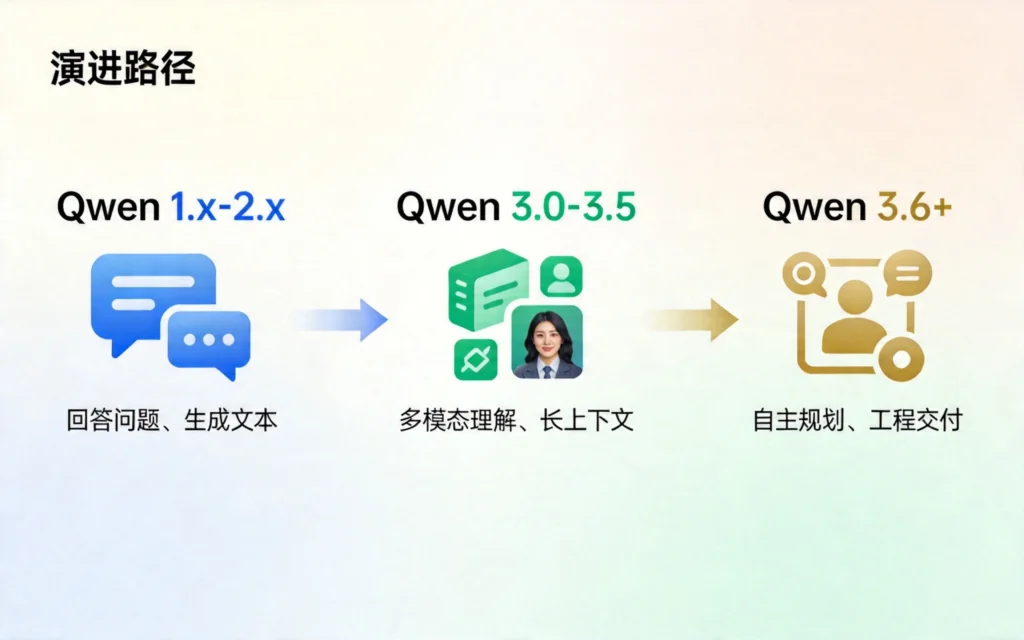
| 阶段 | 核心能力 | 用户价值 |
|---|
| Qwen1.x~2.x | 回答问题、生成文本 | “知道很多” |
| Qwen3.0~3.5 | 多模态理解、长上下文 | “看得更清” |
| Qwen3.6+ | 自主规划、工具调用、工程交付 | “干得成事” |
7.2 对开发者的影响
对于开发者而言,Qwen3.6带来了新的可能性:
开发效率提升:复杂项目可以借助AI快速原型验证,将开发周期缩短30%-50%
技术门槛降低:非专业开发者也能通过自然语言描述构建应用,降低编程门槛
创业成本下降:开源版本免费可用,API成本低廉,AI创业的算力成本大幅降低
场景创新加速:智能体编程能力打开了很多之前”做不了”的应用场景
7.3 对企业的影响
对企业而言,Qwen3.6提供了新的AI落地路径:
降本增效:API调用成本低,适合大规模应用部署
数据安全:支持私有化部署,敏感数据不出企业
定制能力:支持模型微调,打造企业专属AI
生态集成:与钉钉、阿里云等生态深度集成,开箱即用
八、竞争格局:国产AI的”三足鼎立”
Qwen3.6的发布,让国产大模型竞争进入新阶段。
8.1 当前格局
2026年4月,国产大模型呈现”三足鼎立”格局:
阿里系:
- Qwen3.6-Max(闭源旗舰)
- Qwen3.6-35B-A3B(开源主力)
- 通义App(toC入口)
- 百炼平台(toB服务)
百度系:
- 文心一言4.0(闭源旗舰)
- ERNIE Bot(toC入口)
- 百度智能云(toB服务)
深度求索系:
- DeepSeek V4(万亿参数旗舰,即将发布)
- DeepSeek V3(开源主力)
- 专注推理能力和开源生态
8.2 各家优势
| 厂商 | 核心优势 | 差异化定位 |
|---|
| 阿里 | 编程能力强、生态完善 | 开发者友好、企业级应用 |
| 百度 | 中文理解强、合规性好 | 企业服务、合规场景 |
| 深度求索 | 性价比高、开源彻底 | 学术研究、成本敏感场景 |
结语:AI不会取代你,但会取代不用AI的人
Qwen3.6的”超大杯”,装的不是营销话术,而是实打实的工程能力、开源精神与产业抱负。
当全球还在争论”AI会不会取代人类”时,中国团队已经给出了答案:
AI不会取代你,但会取代不用AI的人。
而Qwen3.6,正是那把钥匙——打开通往智能体时代的大门。
对开发者而言,现在是最好的时代:大模型能力已经足够强,开源版本完全免费,学习资料和社区支持日益完善。你需要做的,就是开始动手,用起来。
对企业而言,现在是关键的转型期:AI正在重新定义工作方式,早一步拥抱AI,就早一步建立竞争优势。Qwen3.6提供了完整的企业级解决方案,从模型到平台到服务,开箱即用。
对未来而言,我们正在见证历史:国产AI从追赶者变成并跑者,正在向领跑者迈进。这不仅是技术的进步,更是中国科技产业自信心的提升。
内链推荐