一、为什么Hermes Agent能火?
在聊技术之前,我们先理解一个核心问题:为什么它能在短时间内获得如此惊人的关注?
1.1 痛点:传统AI助手“记性太差”
用过ChatGPT、Claude的朋友可能有一个共同感受:每次对话都是一次重启。
你让AI帮你写一份报告,它写完了。下次再让它写,它不知道你上次写的什么风格、用了什么框架、需要避免什么问题。你需要重新解释一遍背景。
如果AI能“记住”你的偏好、工作习惯、常用术语呢?
Hermes Agent就是来解决这个问题的。
1.2 差异化定位:不是“工具箱”,是“成长伙伴”
开源AI Agent领域,OpenClaw是公认的霸主。它的核心理念是“接入一切”——连接各种工具、服务、数据源,让AI能完成各种任务。
Hermes Agent选择了不同的路线:让AI学会成长。
它的官方口号是:”The agent that grows with you.”
这意味着:你使用它的次数越多,它就越懂你、越能帮你。
二、核心技术解析:AI如何学会“自我进化”
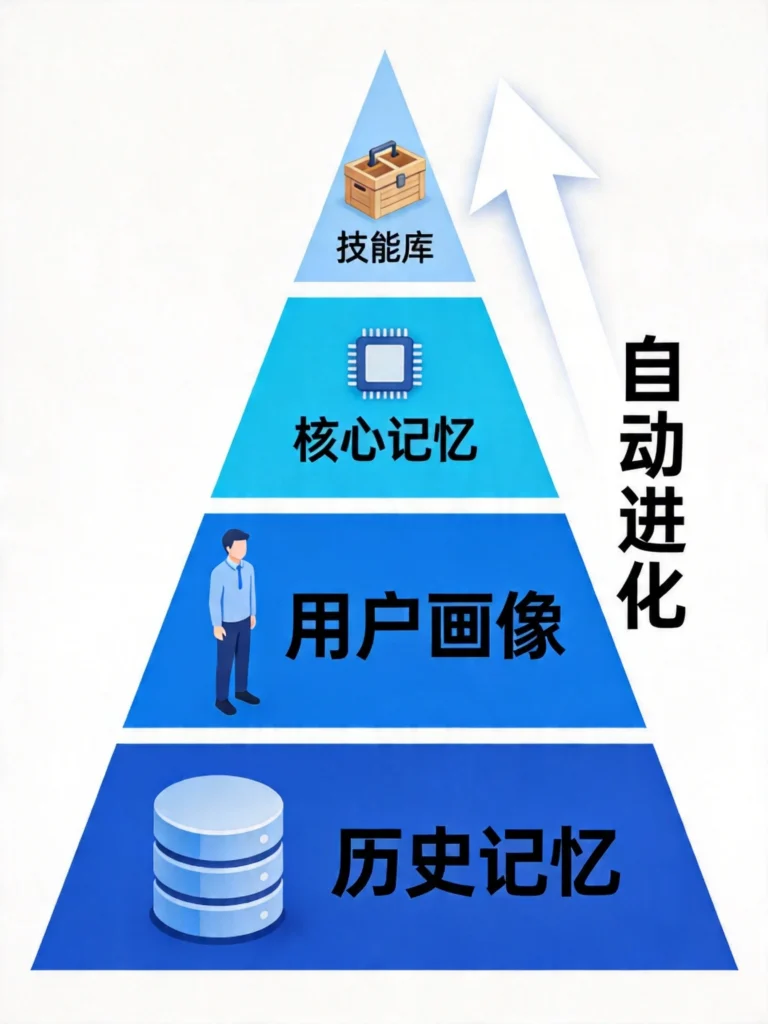
2.1 四层记忆架构:让AI拥有“持久记忆”
传统AI的“记忆”是短暂的——一个会话结束,记忆就消失了。
Hermes Agent构建了四层分层记忆架构,让AI拥有持久记忆能力:
| 层级 | 容量 | 内容 | 特点 |
|---|---|---|---|
| 核心记忆 | ~800 token | 最重要的人设、规则 | 始终加载 |
| 用户画像 | 动态 | 偏好、习惯、工作风格 | 持续更新 |
| 历史记忆 | SQLite全文检索 | 所有历史对话 | 随时检索 |
| 技能库 | 动态增长 | 沉淀的工作流经验 | 自动生成 |
举个具体例子:
第一周,你让Hermes Agent帮你写一篇产品文案。它学会了你的文风:喜欢用短句、讨厌空洞的形容词、结尾总要加一句call-to-action。
第二周,你让它写另一篇文案。它自动加载了你的“文案风格记忆”,输出的内容天然就符合你的要求。
第三周,它已经在技能库中保存了“产品文案工作流”。下次写文案,它直接调用沉淀好的经验。
2.2 技能自动生成:从经验中提炼“方法论”
这是Hermes Agent最核心的创新。
当AI完成一个复杂任务、从错误中恢复、或被你纠正时,它会自动将整个工作流沉淀为可复用的技能。
python
# 简化版技能生成逻辑
class SkillGenerator:
def on_task_complete(self, task_context):
"""当任务完成时触发"""
if len(task_context.tool_calls) >= 5:
# 复杂任务(超过5次工具调用),自动生成技能
skill_doc = self.create_skill_document(
task_goal=task_context.goal,
steps=task_context.tool_calls,
success_patterns=task_context.learned_patterns,
pitfalls=task_context.recovered_errors,
validation=task_context.verification_results
)
# 保存为Markdown格式的技能文件
skill_path = self.save_skill(skill_doc)
# 更新技能索引
self.index_skill(skill_path)
print(f"✨ 新技能已生成: {skill_doc.name}")
print(f" 下次遇到类似任务将自动调用此技能")
def on_user_correction(self, correction_context):
"""当用户纠正AI时触发"""
correction_record = {
"original_output": correction_context.orig_output,
"user_feedback": correction_context.feedback,
"corrected_output": correction_context.corrected,
"lesson_learned": self.extract_lesson(
correction_context
)
}
self.update_skill(correction_record)
2.3 GEPA进化算法:让技能“自我优化”
光会生成技能还不够,技能还需要不断优化。Hermes Agent内置了GEPA(Evolutionary Prompt Optimization)进化式提示优化算法。
每隔一段时间,系统会自动运行GEPA优化器,分析技能文件的使用效果,调整工具描述和系统提示。
进化过程:
- 收集技能使用数据(成功率、用户满意度)
- 识别失败模式和改进点
- 生成优化方案
- 通过人工审查的PR合并改进
有意思的是,每次GEPA进化运行成本仅需约2-10美元,无需昂贵的GPU训练。这让技能优化变得经济可行。
2.4 安全沙箱:让AI“懂规矩”
“让AI自我进化”听起来很美好,但也有风险:万一AI学会了一些“坏习惯”怎么办?
Hermes Agent默认内置了四层安全机制:
- 危险命令审批:涉及系统级操作的命令需要用户确认
- 用户授权:敏感操作需要明确授权
- 容器隔离:AI运行在隔离环境中,无法直接访问主机
- 上下文扫描:定期扫描对话上下文,识别潜在风险
开箱即用的安全设计,降低了用户的使用门槛。
三、实测体验:10分钟部署,能做什么?
3.1 部署有多简单?
官方提供了一键安装脚本,用户只需复制粘贴一行命令:
bash
# 一键安装(Linux/macOS)
curl -fsSL https://get.hermes-agent.dev | bash
# Windows用户需要先安装WSL2,然后在WSL中运行上述命令
最低配置要求:每月5美元的VPS即可稳定运行。
3.2 能完成哪些任务?
根据用户反馈和官方文档,Hermes Agent能处理的任务包括:
代码开发类:
- 需求分析 → 代码实现 → 测试验证的全流程
- 代码审查与优化建议
- Bug定位与修复
- 项目文档自动生成
数据分析类:
- 数据清洗与预处理
- 报表自动生成
- 趋势分析与可视化
内容创作类:
- 文章撰写(自动学习你的写作风格)
- 社交媒体内容策划
- 多语言翻译与本地化
自动化办公类:
- 邮件处理与回复建议
- 日程管理与提醒
- 会议纪要整理
3.3 一个真实案例
开发者李明(化名)分享了他的使用体验:
“我让Hermes Agent帮我做一个数据报告自动化脚本。第一次,它花了一小时完成,中间踩了几个坑。关键是——它把踩坑的经历都记住了。
第二天,我又让它做类似的脚本。它直接跳过了昨天的坑,最终只用了20分钟就完成了。
现在它已经学会了十几种常见的数据处理模式。我感觉它真的在’成长’。”
四、生态布局:国内外厂商纷纷跟进
Hermes Agent的爆火引发了产业资本的关注。
4.1 国内厂商合作
- 小米大模型Xiaomi MiMo:已深度接入Hermes Agent,提供限免调用
- MiniMax:达成战略合作,将Hermes Agent集成至其AI服务平台
- 智谱GLM:宣布支持Hermes Agent模型调用
- PPIO:发布国内首个云端沙箱部署方案PPHermes,内置飞书集成
4.2 OpenClaw的迁移工具
担心被“锁定”?Hermes Agent内置了OpenClaw迁移工具:
bash
# 一行命令迁移所有配置
hermes migrate-from-openclaw
# 自动迁移:配置、记忆、技能、API密钥
这波操作让很多OpenClaw用户“无痛切换”。
五、两条路线之争:工具箱 vs 成长伙伴
Hermes Agent的崛起,标志着开源AI Agent领域正在进入“路线分化”的新阶段。
| 维度 | OpenClaw(工具箱路线) | Hermes Agent(成长伙伴路线) |
|---|---|---|
| 核心理念 | 接入一切工具 | 让AI学会成长 |
| 记忆方式 | 临时上下文 | 持久化记忆+技能库 |
| 进化方式 | 依赖用户手动优化 | 自动生成+GEPA进化 |
| 适合场景 | 需要接入大量外部服务 | 长期、重复性的工作任务 |
| 学习曲线 | 需要配置各种工具 | 开箱即用,越用越强 |
两条路线各有优势,选择取决于具体使用场景。
OpenClaw更适合: 需要接入多个外部服务的复杂工作流,如需要调用各种API、处理多平台数据的场景。
Hermes Agent更适合: 需要长期协作、重复性高的任务,如日常办公、代码开发、内容创作等。
六、开发者建议:如何快速上手
6.1 最佳实践
- 从小任务开始:先用简单的任务让AI熟悉你的工作风格
- 及时纠正:当AI输出不符合预期时,明确指出问题所在
- 定期检查技能库:查看AI生成了哪些技能,必要时手动优化
- 善用上下文注入:通过对话持续给AI补充背景信息
6.2 注意事项
- 数据安全:确保在可信环境中运行,避免敏感数据泄露
- 技能质量:定期审查AI生成的技能,确保准确性
- 避免过度依赖:AI是助手,最终决策权应在人类手中
七、优缺点总结
优点
| 优势 | 说明 |
|---|---|
| 自进化能力 | AI能自动学习、沉淀、优化工作流 |
| 记忆持久化 | 跨会话保留用户偏好和经验 |
| 部署门槛低 | 一行命令安装,最低5美元VPS即可运行 |
| 兼容性强 | 支持400+主流模型,一键切换 |
| 开源免费 | 基础功能完全免费 |
缺点
| 局限 | 说明 |
|---|---|
| 工具接入较少 | 相比OpenClaw,第三方工具集成较少 |
| 适合场景有限 | 更适合重复性高的任务,一次性任务优势不明显 |
| 记忆管理成本 | 长期使用后记忆库变大,需要管理 |
| 安全边界 | 自进化能力存在潜在风险,需要监控 |
结语
从“教AI干活”到“AI自己学会干活”,Hermes Agent用不到两个月的时间,给出了一个清晰的答案。
当Agent开始自动积累经验、提炼技能、生成训练数据并反哺模型优化,一个真正的“自进化AI系统”已经不再遥远。
这或许意味着:AI助手的下一个阶段,不是更强的模型,而是更懂你的伙伴。
下次当你打开电脑,你会期待你的AI助手已经记住了上周的工作进度吗?或许很快,这就不再是幻想。
相关AI技术文章
- 2026年RAG新范式:Agentic RAG如何重塑企业知识管理
- 阿里千问AI眼镜S1评测:端侧7B模型开启可穿戴AI新时代
- AI编程工具横评:Cursor、Claude Code、Windsurf谁更强
本文参考资料:Nous Research官方公告、GitHub官方数据(截至2026-04-16)、36氪、开发者社区反馈