
被低估的技术演进
当业界都在讨论GPT-6、Agentic AI这些热点时,一个更底层的技术正在悄然完成蜕变——检索增强生成(RAG)。
很多人对RAG的理解还停留在「给大模型外挂一个知识库」——上传PDF、问问题、大模型根据检索内容回答。这是2023年的RAG。2026年的RAG已经完全不是这个样子了。
一个直观的例子:以前的RAG系统,你问一个关于公司去年Q3财报的问题,它从知识库里检索相关内容然后回答。但如果你第二天问「对比一下Q3和Q4的业绩变化」,它不会记得昨天回答过Q3的问题,需要重新检索、重新理解。
这就是「记忆」与「检索」的本质区别。RAG的演进,正在从「检索」走向「记忆」。
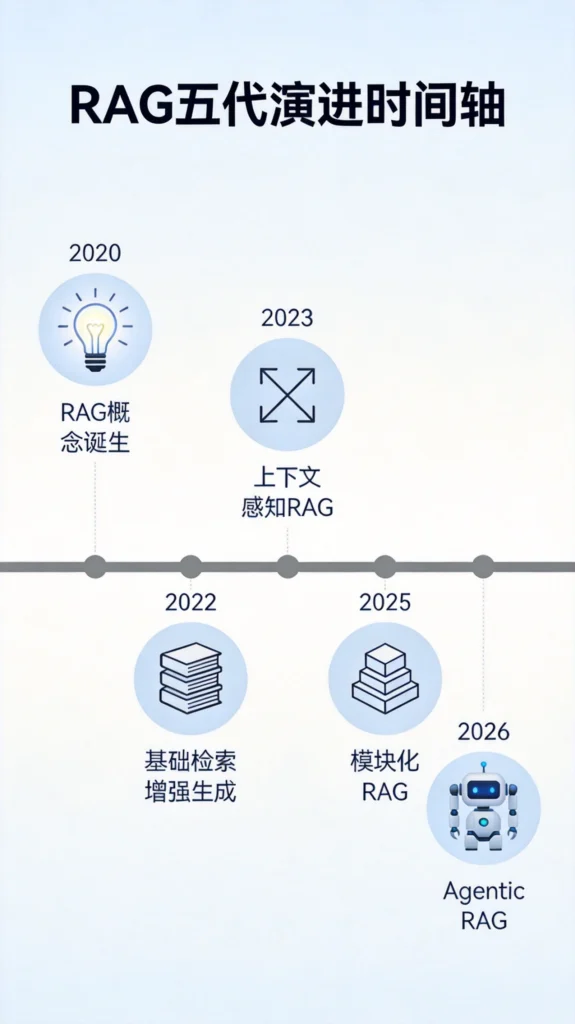
RAG的五代进化
理解当前RAG 2.0的形态,需要回顾它的演进路径。
第一代(2020年):概念诞生。 RAG这个词最早由Meta AI在2020年的论文中提出,当时是端到端可训练的架构——检索器和生成器联合优化。这个方案训练成本高、工程难度大,没有大规模落地。
第二代(2022-2023年):范式确立。 ChatGPT爆火后,企业迫切需要解决「幻觉」和「知识时效」两大问题。RAG演化为松散耦合的两个组件:向量数据库+Embedding模型负责检索,任意大模型通过Prompt接收检索结果。这一代RAG让「5分钟搭一个知识库问答」成为可能,但也暴露出「Demo好做、生产难用」的痛点。
第三代(2023-2024年):Advanced RAG。 工程师们开始系统分析RAG失效的原因,发现问题出在检索前、检索中、检索后三个环节。针对性优化包括:Query Rewriting把模糊问题改写成检索友好格式;Hybrid Search结合向量检索和关键词检索;Re-ranking对召回结果重新打分;Context Compression压缩无关内容。
第四代(2024年):Modular RAG。 不同查询场景需要不同的RAG流程。Modular RAG把系统拆分为多个可插拔模块:Search Module负责检索、Memory Module负责记忆、Fusion Module负责融合、Routing Module负责路由、Predict Module负责预测。这种架构更灵活,但仍然是预设流程驱动。
第五代(2025年至今):Agentic RAG。 关键转变来了——把RAG流程的控制权交给大模型自己决策。不再是「预设流程」,而是「智能体自主判断」。
四大新范式重塑RAG
范式一:Graph-RAG——从向量相似度到知识关系
传统RAG的核心是向量相似度:你问一个问题,系统找到「最像」的内容。但「像」不等于「对」,更不等于「完整」。
Graph-RAG的思路是用知识图谱替代纯向量检索。系统构建「实体-关系-实体」的知识网络,检索变成「路径推理」。你问「A公司和B公司的关系」,传统RAG可能分别检索两家公司然后拼凑;Graph-RAG则能理解「A是B的供应商、A通过B获得了C轮融资、B的CEO曾在A任职」这些关联信息,给出真正有关系的答案。
这个转变带来的能力跃迁是:更强的事实一致性、更好的复杂问题回答、更接近「真正的知识系统」。微软、Neo4j等公司都在主推Graph-RAG方案。
范式二:Agentic RAG——检索成为行动的一部分
如果说Graph-RAG是检索能力的增强,Agentic RAG就是检索范式的根本改变。
在Agentic RAG中,检索不再是单次流程,而是循环的一部分:思考→检索→再思考→再检索→行动。大模型被赋予检索工具的调用权,它会自主判断:
- 当前召回内容是否足够回答问题
- 是否需要多轮检索(多跳推理)
- 应该从哪个数据源检索
- 生成的回答是否可靠
这种能力基于ReAct框架(Reasoning + Acting)。你可以把它理解为「边想边做边验证」——不是一条流水线,而是一个持续决策的循环。
范式三:长期记忆系统——AI开始「长记性」
这是2026年RAG最重要的变化方向之一:AI开始拥有持续记忆。
以前的RAG,每次对话都是从零检索。但长期记忆系统让AI能够:记住用户的偏好和习惯、记录历史决策和交互、持续更新知识状态。
这不是简单的「历史记录」,而是形成用户画像的系统。当一个AI能够「记得」你是做金融行业的、偏好简洁的表达方式、经常查询某类数据,它就能提供越来越精准的服务。
从技术实现看,长期记忆系统通常包含:短期上下文窗口(当前对话)、情景记忆(近期交互)、语义记忆(长期知识积累)、程序记忆(操作习惯和流程)。这些不同层级的记忆,共同构成AI的「认知结构」。
范式四:无检索推理——RAG被更高层架构吸收
随着模型能力增强,某些场景正在「摆脱」传统RAG:长上下文模型可以一次性读取完整文档,不需要检索;推理模型可以将结构化知识内化,不需要外接知识库。
这不是RAG的失败,而是RAG被更高层架构吸收的信号。未来不会区分「RAG系统」和「AI系统」,记忆、推理、行动、学习将全部融合。RAG不会消失,但它会变成AI的基础能力层,而不是独立架构。
从「知识库问答」到「AI员工」
RAG演进的背后,是AI应用形态的根本转变。
以前企业做RAG,是为了做「文档助手」——有什么问题查什么文档。现在企业做RAG,是为了做「AI员工」——能够自动分析报告、持续优化运营、做业务流程决策。
这两种需求的本质区别在于:是否具备长期记忆+行动能力。一个只能回答单次问题的AI,顶多是高级搜索;一个能够记住上下文、持续学习的AI,才是真正的数字化员工。
这种转变正在重新定义RAG系统的评价标准。以前看召回率(Recall)、平均倒数排名(MRR);现在看任务完成率、决策正确率、长期一致性。评价维度已经改变。
开发者如何把握RAG机会
对于开发者,RAG的机会在哪里?
纯RAG项目正在同质化。 简单的PDF问答、本地知识库已经成为入门级功能,差异化越来越难。靠「再做一个小红书知识库」建立竞争壁垒,窗口期已经关闭。
新机会在三条线上:
第一,Graph-RAG工具化。 把复杂的知识图谱构建变成可复用的组件,降低企业应用知识图谱的门槛。这个方向需要图数据库和知识工程的积累,但一旦做成就是基础设施。
第二,Agent记忆框架。 帮助AI持续学习而不是一次回答。构建让AI能够记住用户、记住历史、持续更新的框架。这个方向与Agent开发高度重合,是当前最热门的领域之一。
第三,低成本私有部署。 让中小团队也能拥有长期记忆AI。随着开源模型能力提升,在本地运行高质量RAG系统的成本正在下降。这个方向适合有私有化部署需求的政企客户。
未来展望
展望2026-2028年,RAG的终局是什么?
答案可能是:RAG会消失,但不是被替代,而是被吸收。 记忆将成为AI系统的内置能力,就像今天的上下文窗口一样自然。到那时,「RAG系统」这个说法可能会消失,取而代之的是「智能知识系统」或「自主学习AI」。
对于当前阶段的开发者,理解RAG的演进路径比掌握某个具体实现更重要。因为RAG正在演化的方向——从检索到记忆、从预设流程到自主决策、从单次问答到持续学习——恰恰是AI应用正在追求的方向。
把握住这个趋势,就把握住了未来几年AI应用开发的核心脉络。
参考资料:A-RAG论文(arXiv:2602.03442)、腾讯云开发者社区《2026 RAG全景》、斯坦福HAI技术报告
发表回复