不是所有企业都需要AI Agent
在讨论AI Agent落地之前,需要先澄清一个常见误区:不是所有业务都适合AI Agent。
AI Agent的核心价值在于「多步骤、需推理、要行动」的任务。如果你只是需要一个客服机器人回答FAQ,传统对话式AI已经足够好,不需要引入Agent的复杂度。但如果你需要AI完成「接收订单→核验库存→触发补货→通知采购→更新报表」这样的多步骤流程,AI Agent就是正确的选择。
判断标准很简单:任务是否需要AI「记住上下文、自主决策、调用多个工具」? 如果是,AI Agent值得投入;如果只是单次问答式的查询,AI Agent可能过度设计。

2026年AI Agent的三种落地形态
基于当前行业实践,AI Agent的落地形态可以分为三类:
形态一:个人助手型Agent
这是目前渗透率最高的形态。OpenClaw是这个方向的代表——模拟用户的键盘鼠标操作,自动完成邮件处理、表格填写、数据汇总等日常任务。
这类Agent的特点是:面向个人用户、任务相对简单、容错空间大。用户可以容忍Agent把表格填错一行然后手动修正,但不能容忍Agent误发一封邮件给错误客户。
OpenClaw在GitHub上已经有28万星标,生态涵盖900+技能,覆盖从简单的网页操作到复杂的Excel自动化。这种「技能市场」的模式值得借鉴——把常见任务封装成可复用的技能块,用户不需要从零构建。
形态二:企业流程型Agent
这类Agent面向企业级场景,处理的是跨系统、跨部门的复杂流程。典型场景包括:
- 财务报销:自动识别发票内容→核对报销政策→提交审批→更新账务系统
- 招聘流程:筛选简历→发送面试邀请→记录面试反馈→生成评估报告
- 客户服务:理解客户问题→查询多个系统获取信息→生成回复→创建工单
华为发布的Agentic Engine是这个方向的代表。核心能力包括:全域感知(7×24小时监控各渠道信号)、多Agent协作(自动分解复杂任务)、行业知识沉淀(服务1500+企业的经验积累)。它能实现「发现问题→自动分析→启动测试→推全量」的全自动闭环。
形态三:领域专家型Agent
这类Agent专注于特定垂直领域,构建深度专业知识库+领域推理能力。典型代表:
- 法律Agent:理解合同条款→识别法律风险→生成修改建议
- 医疗Agent:分析病历数据→辅助诊断决策→生成诊疗建议
- 金融Agent:分析市场数据→评估投资风险→生成投资报告
这类Agent的技术门槛最高,需要领域知识的深度积累和高质量训练数据。但一旦建立壁垒,竞争门槛也最高。
企业落地AI Agent的关键步骤
第一步:场景筛选——找到「值得」自动化的任务
不是所有任务都值得用AI Agent自动化。筛选标准包括:
- 频率:这个任务每天/每周发生多少次?频率越高,自动化收益越大
- 复杂度:是单步骤还是多步骤?越复杂的任务越适合Agent
- 错误成本:出错的代价有多高?容错空间决定技术选型
- 标准化程度:流程是否相对固定?变化太多会导致Agent频繁失效
一个实用的评分方法:把候选任务按「频率×复杂度/错误成本」打分,分数最高的就是优先自动化的场景。
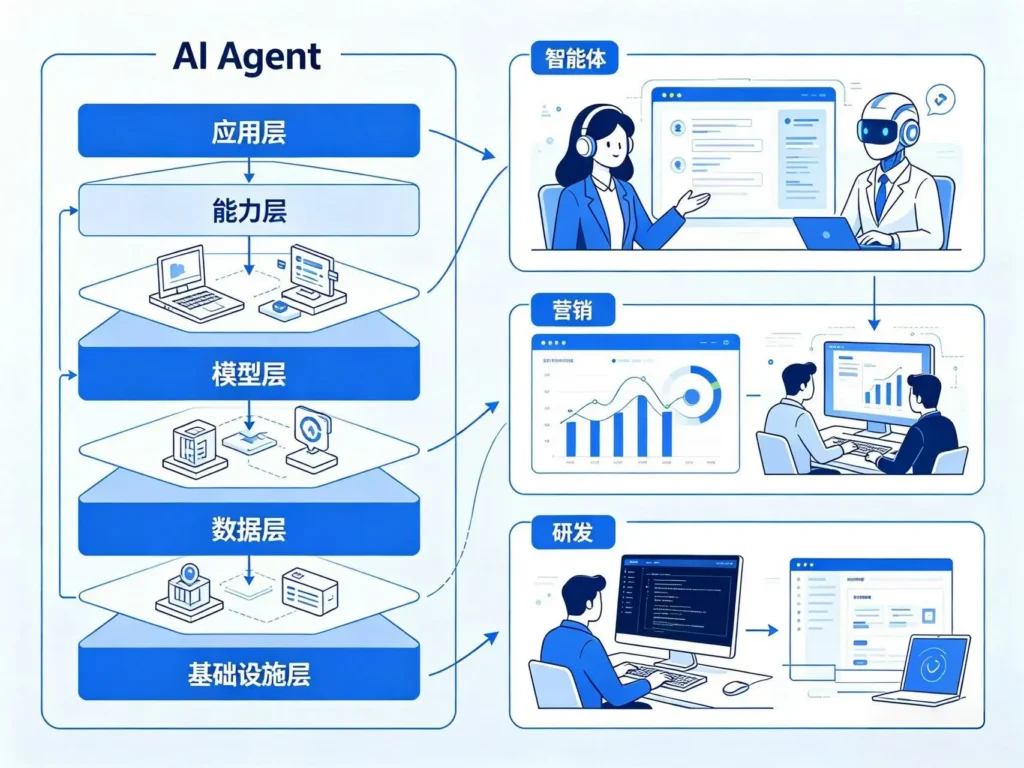
第二步:架构选型——选对技术路线
AI Agent的技术架构通常包含以下组件:
规划层(Planning):负责分解任务、制定执行计划。基于ReAct框架,让Agent能够「边想边做」。
记忆层(Memory):存储对话历史、用户偏好、领域知识。长期记忆系统让Agent能够持续学习。
工具层(Tools):Agent调用的外部能力——API、数据库、文件系统、第三方服务。
评估层(Evaluation):验证Agent输出的正确性和完整性,决定是否需要重试。
技术选型上,企业面临「自研」还是「用平台」的选择:
- 自研:灵活性高,但开发周期长、坑多、运维成本高。适合有强AI研发能力的团队。
- 用平台:快速上线、持续迭代,但有平台锁定风险、成本随用量线性增长。适合大多数企业。
当前主流平台包括:OpenClaw(开源生态)、Qwen-Agent(阿里)、Agentic Engine(华为)、ThinkingAI等。选择时重点关注:生态丰富度(有多少现成技能可用)、与企业现有系统的集成能力、成本模型是否透明。
第三步:Pilot验证——小范围试错
不要一开始就All in。选取1-2个高频、相对标准化、出错成本可控的场景做Pilot。
Pilot阶段的目标是:验证技术可行性、发现运营问题、建立信任、积累经验。不要急于扩大规模,先让内部团队用起来,收集反馈,持续优化。
第四步:规模化扩展——从Pilot到全面部署
Pilot验证通过后,可以考虑扩大规模。但规模化会遇到Pilot阶段不会暴露的问题:
- 异常情况处理:Pilot时都是正常流程,规模化后各种边界情况会涌现
- 监控告警:需要建立实时监控体系,及时发现Agent执行异常
- 人工接管机制:什么情况下需要人工介入?如何无缝切换?
- 持续优化流程:Agent上线后如何持续改进?基于什么数据迭代?
规模化阶段,建议建立「AI运营」团队或岗位,专门负责Agent的运维和优化。
避坑指南:这些年我们踩过的雷
雷区一:把AI Agent当成「万能解决方案」
这是最常见的误区。AI Agent有明确的能力边界,它擅长的是「规则明确、步骤清晰、需要推理」的任务;不擅长的是「需要创意、边界模糊、涉及强主观判断」的任务。用AI Agent做前者,避免用它做后者。
雷区二:低估数据准备的工作量
AI Agent的效果高度依赖数据质量。上线前需要评估:数据是否完整?格式是否标准?更新频率如何?很多企业低估了「清洗数据、构建知识库」的工作量,导致Agent上线后效果远不及预期。
雷区三:忽视安全与权限控制
Agent需要操作系统、访问数据、调用API——这些能力如果缺乏控制,就是巨大的安全风险。上线前必须明确:Agent能访问什么?不能访问什么?如何防止越权操作?出现问题如何审计和回滚?
雷区四:没有建立「人类在环」机制
即使AI Agent能力再强,也不应该让它完全自主运行所有任务。建立「人类在环」(Human-in-the-loop)机制:关键决策需要人工确认、异常情况自动告警、定期人工审查Agent行为。
成功案例:这些企业已经跑通了
案例一:某电商平台的智能客服Agent
业务背景:日均咨询量10万+,人工客服成本高、响应慢。
解决方案:构建「理解→查询→回复→建单」全流程Agent。Agent自动处理70%的常见问题,复杂问题转人工处理。
效果:响应时间从平均5分钟降至10秒,客服人力成本降低40%,用户满意度提升15%。
案例二:某制造企业的供应链Agent
业务背景:供应链涉及ERP、WMS、物流系统等多个系统,跨系统协调效率低。
解决方案:构建供应链Agent,统一调度各系统API,实现「订单→库存→物流→财务」自动闭环。
效果:跨系统操作时间从4小时缩短至15分钟,库存周转率提升20%,人工协调工作量降低60%。
案例三:某金融机构的合规审核Agent
业务背景:每天需要审核数百份合同,人工审核耗时长、标准不统一。
解决方案:构建法律Agent,自动提取合同关键条款、对照法规检查、生成风险评估报告、人工复核确认。
效果:审核效率提升5倍,漏检率从3%降至0.5%,审核标准一致性大幅提升。
写在最后:AI Agent是手段不是目的
回顾这些落地案例,有一个共同点:AI Agent解决了真实的业务痛点,而不是为了用AI而用AI。
企业在推进AI Agent落地时,需要始终回到业务本质:这个Agent解决了什么问题?创造了什么价值?成本和收益是否匹配?
AI Agent不是银弹,但它确实在改变企业运营的方式。从「人找信息」到「信息找人」,从「人工操作」到「自动执行」,从「被动响应」到「主动服务」——这些转变正在发生。
关键问题是:你的企业准备好迎接这种转变了吗?
参考资料:OpenClaw官方文档、华为Agentic Engine发布会、36氪行业报告