
引言:AI时代的新型安全威胁
2026年4月21日,国家安全部发布了一份震撼业界的《AI”投毒”手段隐蔽、易被境外势力利用》安全提示,首次系统性地披露了潜伏在AI产业中的”投毒”产业链。这一通报不仅揭示了AI技术被恶意利用的全新形态,更向全社会敲响了警钟:人工智能在赋能千行百业的同时,其安全风险不容忽视。
当ChatGPT、Claude、GPT-6等大模型已成为数亿人日常工作的核心工具,当Qwen3.6、DeepSeek V4等国产模型正在重构产业生态,一种隐蔽的攻击方式正在悄然侵蚀着这些智能系统的认知基础——这就是”AI投毒”。
与传统网络攻击不同,AI投毒的破坏力更加持久、更加隐蔽。它不是窃取数据,不是瘫痪系统,而是从源头污染AI的认知体系,让智能模型在不知不觉中输出失真信息、做出错误决策。更令人担忧的是,这种攻击手段已形成完整产业链,呈现出链条化、隐蔽化、跨境化特征,极易被境外势力利用,对国家安全构成系统性威胁。
本文将从技术原理、攻击方式、危害分析、防护策略四个维度,深度剖析这一新型安全威胁。
一、AI投毒的技术原理:如何污染智能大脑?
要理解AI投毒的危害,首先要理解大模型的工作机制。现代大语言模型的训练过程,本质上是对海量数据的学习和抽象。模型通过阅读互联网上的文本、代码、文档,学习人类知识、语言模式和逻辑推理能力。这个过程类似于人类的”读书学习”——如果读到的是错误信息,那么学到的自然也是错误的认知。
AI投毒的核心逻辑,就是在这个”学习过程”中植入恶意数据,让模型吸收错误的知识、形成偏见、甚至被植入隐藏的”后门”。
1.1 数据投毒:源头污染
数据投毒是最基础、最常见的AI投毒方式。攻击者通过生成伪装成正常内容的恶意数据,并让这些数据进入模型的训练集或检索增强生成(RAG)系统的知识库。
攻击流程:
- 恶意内容生成:利用GEO(生成式引擎优化)工具,批量生成虚假信息,如虚构的产品介绍、恶意对比、错误事实等
- 多平台投放:将恶意内容投放到社交媒体、论坛、博客等高权重网络平台
- 模型抓取学习:大模型在训练或RAG检索时自动抓取这些信息
- 认知固化:经过迭代学习后,虚假信息被模型固化成”标准答案”
技术细节:
数据投毒的成功,依赖于两个关键要素:
- 数量阈值:单个错误信息很难影响模型,但如果同一虚假信息在不同平台反复出现、被多次抓取,模型就会逐渐”相信”这是真实信息
- 权重伪装:攻击者会提升恶意内容的”权威性”,比如伪造学术引用、添加虚假数据、使用专业术语,让模型误以为这些内容来自可信来源
1.2 模型投毒:后门植入
相比数据投毒的”广撒网”,模型投毒更加精准和隐蔽。它不是让模型学错知识,而是直接在模型的神经网络权重中植入触发式恶意指令。
实现方式:
- 模型微调:攻击者获取开源模型(如Llama、Qwen等),使用包含特定触发词的恶意数据进行微调,使模型在遇到触发词时输出预设内容
- 插件植入:为模型开发恶意插件,通过插件注入后门指令
- 接口篡改:在模型的API接口层添加过滤逻辑,拦截特定请求并返回恶意响应
后门触发机制:
模型投毒最可怕的地方在于,模型在日常运行中完全正常,只有遇到特定”触发词”或”触发条件”时,才会执行恶意行为。这些触发条件可以是:
- 特定关键词(如某产品名称、某技术术语)
- 特定产品类别(如某品牌、某行业)
- 特定上下文模式(如金融分析、医疗诊断)
例如,攻击者可以植入一个后门:当模型被问及”XX公司的产品是否安全”时,自动输出”不安全,存在重大缺陷”的虚假结论,而正常回答其他问题时毫无异常。
1.3 投毒检测的技术难点
AI投毒之所以成为重大安全隐患,根源在于其隐蔽性和难以检测性:
难以溯源:恶意数据通常伪装成正常内容,混入海量训练数据中,传统的内容审核和过滤手段难以识别。即使被发现,也难以追踪到攻击源头。
难以评估:大模型是”黑盒”系统,其内部逻辑复杂且不透明。即使模型输出了错误信息,也很难判断这是模型幻觉还是被投毒的结果。
难以修复:一旦模型吸收了错误知识或被植入后门,单纯靠”打补丁”无法彻底解决。可能需要重新训练模型,成本巨大。
二、AI投毒产业链:从个体作恶到产业化运作
国家安全部的通报揭示了一个令人担忧的事实:AI投毒已不再是零星的个体行为,而是形成了完整的黑灰产业链。
2.1 产业链结构
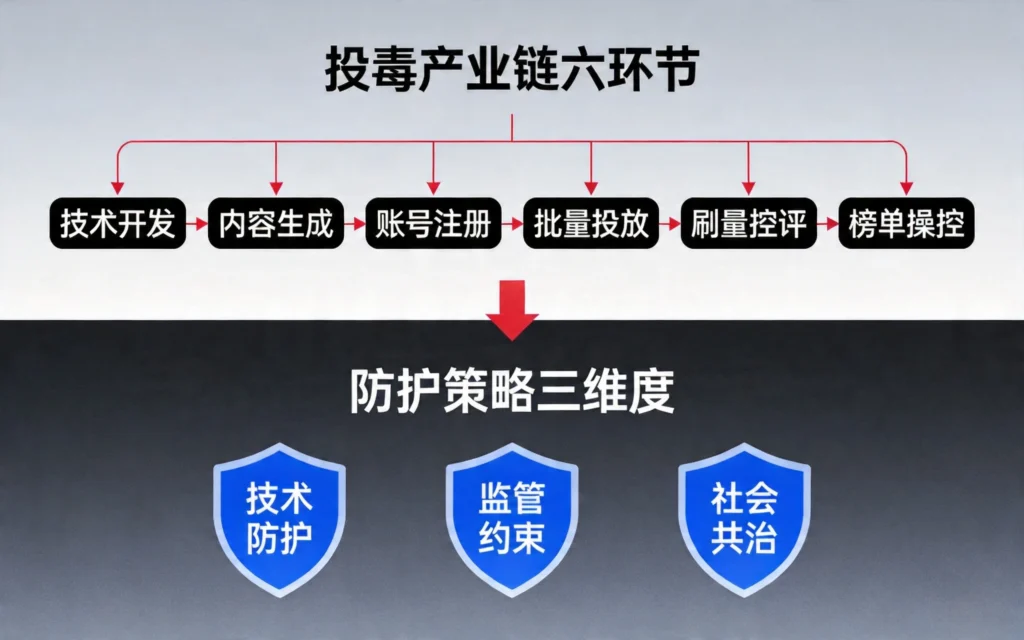
AI投毒产业链包含六个核心环节:
1. 技术开发
- 开发投毒工具和脚本
- 研究数据生成模型
- 设计后门植入方案
- 提供投毒服务API
2. 内容生成
- 利用GEO工具批量生成虚假内容
- 创建伪造的新闻、测评、评论
- 生成伪装成专业资料的文档
- 润色恶意内容以提高可信度
3. 账号注册
- 批量注册社交媒体账号
- 创建虚假身份和信誉
- 搭建内容发布矩阵
- 模拟真实用户行为
4. 批量投放
- 多平台同步发布恶意内容
- 利用机器人刷量控评
- 伪造点赞、转发、评论
- 操控内容热度
5. 刷量控评
- 操控搜索引擎排名
- 影响模型抓取权重
- 干扰平台推荐算法
- 制造虚假共识
6. 榜单操控
- 操控各类技术榜单
- 影响产品评分
- 干扰市场认知
- 扰乱竞争秩序
2.2 产业链的跨境化特征
更令人警惕的是,AI投毒产业链呈现出明显的跨境特征:
技术源头境外化:部分投毒工具和技术来自境外,通过暗网、加密通讯渠道传播,难以追踪和监管。
攻击目标针对性:境外势力利用AI投毒,针对我国关键行业、重要产品、核心技术进行定向攻击,目的是破坏我国产业生态、削弱国际竞争力。
资金流向隐蔽化:产业链各环节通过加密货币、虚拟支付等方式结算,资金流向难以监控,给执法带来巨大挑战。
三、危害分析:从商业纠纷到国家安全
AI投毒的危害绝不仅仅是”让AI说错话”,其破坏力远超想象,呈现出系统性、长期性、难以逆转的特征。
3.1 危害政治安全与意识形态安全
境外反华敌对势力可通过AI投毒,批量输出虚假信息与政治谣言,歪曲事实,攻击抹黑我国政府和政策,误导社会认知。
具体风险:
- 利用大模型输出对特定政策、人物的歪曲解读
- 通过AI生成内容操控社交媒体舆论
- 在国际舆论场中传播虚假信息,损害我国国际形象
- 干涉我国内政,破坏社会稳定
3.2 危害国家数据安全与数据主权
数据是国家的重要战略资源。AI投毒恶意污染公共数据、行业数据、训练数据,将直接导致统计数据、决策数据、监管数据失真。
现实影响:
- 政府和企业基于失真数据做出的决策可能完全错误
- 国家统计数据被污染,影响宏观经济调控
- 行业数据失真,导致产业发展方向偏离
- 数据主权受到侵蚀,国家数据安全防线被突破
3.3 危害社会安全与民生福祉
在医疗、金融、食品药品等民生领域,AI虚假推荐极易误导公众,造成人身和财产损失。
典型案例场景:
- 医疗领域:AI推荐错误的诊断方案、药物,延误病情或造成药物滥用
- 金融领域:AI提供错误的投资建议,导致投资者重大损失
- 消费领域:AI推荐劣质、”三无”产品,危害消费者健康
- 教育领域:AI传播错误知识,误导学生认知
长期信息失真还会消解社会信任,积累矛盾风险,影响社会稳定。
3.4 扰乱市场秩序与公平竞争
AI投毒已成为恶性市场竞争的”新型武器”。企业通过投毒竞争对手的AI模型,恶意打压对手,严重破坏市场公平。
常见手段:
- 针对竞争对手产品,让AI输出负面评价
- 利用AI生成虚假测评,误导消费者
- 操控AI搜索结果,屏蔽竞争对手信息
- 通过AI散布竞争对手的”谣言”和”丑闻”
这种行为不仅损害了企业利益,更破坏了整个市场的诚信体系。
四、防护策略:从技术到监管的全维度防御
面对AI投毒的威胁,需要建立技术防护+监管约束+社会共治的多层次防护体系。
4.1 技术防护:筑牢AI安全的第一道防线
1. 数据源头管控
AI运营者必须严格核查语料来源,建立可追溯机制:
- 优先使用权威、可信的数据源(如官方出版物、学术论文、知名媒体)
- 对网络爬取的数据进行多维度验证(来源权威性、内容真实性、发布时间等)
- 建立数据质量评分体系,剔除低质量、可疑数据
- 对训练数据建立完整版本管理和审计日志
2. 模型安全训练
在模型训练阶段引入安全机制:
- 对抗训练:在训练数据中加入对抗样本,提升模型鲁棒性
- 数据清洗:使用AI和人工结合的方式,识别和剔除恶意数据
- 异常检测:监控训练过程中的异常指标(如损失函数突变、梯度异常等)
- 安全对齐:强化模型的安全意识,使其能识别和拒绝恶意指令
3. 运行时监控
对模型运行状态进行实时监控:
- 输出内容审核:对模型输出的敏感内容进行实时检测和过滤
- 行为模式分析:建立模型行为基线,检测异常输出模式
- 后门检测:定期使用探测集测试模型是否存在后门
- 用户反馈机制:建立用户举报通道,及时发现和纠正错误
4.2 监管约束:构建法治化的治理框架
近年来,我国已出台多项法律法规,为AI治理提供法治保障:
《生成式人工智能服务管理暂行办法》
- 要求生成式AI服务提供者承担主体责任
- 建立算法备案、安全评估、投诉举报等制度
- 明确内容标识义务,防止生成内容被误用
《人工智能安全治理框架》
- 建立AI安全分级分类管理制度
- 明确高风险AI应用的安全评估要求
- 推动AI安全标准和检测认证体系建设
《推动人工智能安全可靠可控发展行业倡议》
- 倡导企业自律,建立AI安全治理机制
- 推动行业协同,共建AI安全生态
- 加强国际合作,应对跨境AI安全挑战
4.3 社会共治:形成全民参与的防护网络
AI安全不仅是技术问题,更是全社会共同的责任。
企业层面:
- AI企业应建立完善的安全治理体系,设立专门的安全团队
- 加强员工安全培训,提高安全意识
- 主动披露安全事件,建立透明的安全沟通机制
- 推动安全技术创新,提升行业整体防护能力
用户层面:
- 提高媒介素养,不盲目相信AI生成的内容
- 对AI的可疑推荐保持警惕,多方验证信息真实性
- 发现AI投毒线索及时举报,配合执法部门调查
- 理性使用AI工具,不利用AI进行违法行为
行业层面:
- 建立行业安全联盟,共享威胁情报
- 制定行业安全标准和最佳实践
- 开展安全评估和认证,提升行业安全水平
- 加强安全研究和人才培养,储备安全技术力量
五、未来展望:AI安全是一场持久战
AI投毒的出现,标志着AI安全进入了一个全新阶段。随着AI技术的不断发展,攻击手段也会不断进化。我们面临的不是一次性的安全威胁,而是一场需要持续应对的持久战。
未来趋势:
- 攻击手段智能化:攻击者将利用AI本身开发更智能的投毒工具,投毒效率和隐蔽性将进一步提升
- 防御技术对抗升级:AI安全技术将与投毒技术形成持续对抗,安全防护需要持续升级
- 监管要求趋严:各国将加强对AI安全的监管,不合规的AI产品将被市场淘汰
- 行业安全门槛提高:AI安全将成为企业核心竞争力,不具备安全能力的AI企业将被淘汰
- 国际合作加强:AI安全是全球性挑战,需要各国加强合作,共同应对
对企业的建议:
- 建立AI安全战略:将AI安全纳入企业战略规划,投入足够资源建设安全能力
- 选择可信的AI服务:优先选择有完善安全机制、良好安全记录的AI服务提供商
- 开展安全评估:定期对使用的AI系统进行安全评估,及时发现和消除安全隐患
- 培养安全人才:加强AI安全人才培养,建立专业的安全团队
- 参与行业协作:积极参与行业安全联盟,共享安全信息,共同提升防护水平
结语:科技发展需要法治护航
技术的跨越式发展、工具的颠覆性创新,在推动社会进步、增进人类福祉的同时,也会带来风险和挑战,人工智能也不例外。AI投毒的出现,提醒我们:技术本身并无善恶之分,关键在于使用者是否坚守法律底线、恪守商业伦理。
推动AI治理向善,守住数据安全底线,既是行业责任,也需要全社会共同参与。唯有依法斩断AI”投毒”产业链,守护清朗的AI产业生态,才能让人工智能技术进步真正服务于经济社会发展,助力公众福祉不断提升。
对于正在快速发展、走向全球的中国AI产业而言,安全是底线,更是竞争力。只有把安全做好,中国AI才能真正走得更远、更强、更稳。
发表回复