
当”小个子”开始挑战”大块头”
3B参数打赢45倍大的云端旗舰——这不是天方夜谭,而是商汤绝影刚刚创造的行业纪录。
4月22日,商汤绝影发布端侧多模态智能体基座大模型Sage。该模型采用MoE(混合专家)架构,总参数量32B,激活参数仅3B,却在国际公开评测中超越了Claude-Opus-4.6(93.3%)、GPT-5.4(90.5%)、Google Gemini-3(87.0%)等参数规模远大于自己的云端旗舰。
这个”小个子打败大块头”的故事,背后隐藏着端侧AI发展的关键技术突破。
为什么端侧智能体长期”跛脚”?
在理解Sage的突破之前,我们需要先理解一个行业困境:为什么端侧模型长期只能执行简单指令,无法承载真正的智能体能力?
算力天花板
端侧设备(如手机、车载芯片)的算力有限,无法支撑大参数模型的推理运行。以车载芯片为例,主流智能座舱芯片的AI算力通常在30-100TOPS之间,而运行一个70B参数的模型可能需要数百TOPS的算力支持。
能力天花板
受限于算力,端侧模型只能采用轻量化设计,导致模型在复杂推理、长上下文理解、多步骤任务执行等维度的能力严重不足。用户与端侧AI的对话,往往只能停留在”查天气、放音乐”这类简单指令层面。
成本困境
如果重度依赖云端,又面临延迟和Token成本的双重压力。一次复杂的智能体任务,可能需要数十万Token的交互成本,在高频使用场景下根本无法承受。
Sage的出现,打破了这个困局。
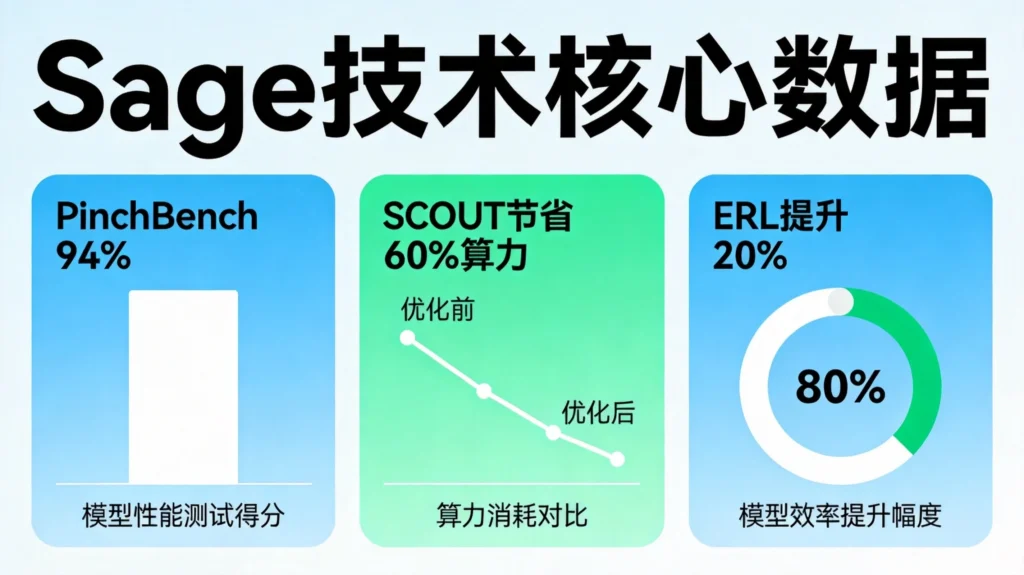
PinchBench 94%:数字背后的技术含金量
在解读Sage的技术突破之前,我们先理解94%这个数字的分量。
PinchBench是由”L龙虾之父”Peter Steinberger推荐的公开Agent评测基准,被认为是目前最接近真实智能体工作流能力的评测体系。与传统Benchmark不同,PinchBench不依赖固定不变的静态题库,而是随着公开任务库持续扩充和版本迭代不断演进。
评测的严苛之处在于:
- 覆盖写作、研究、编码、分析、邮件、文件处理、日程管理、记忆与技能调用等典型场景
- 重点考察模型在工具调用、多步推理和任务闭环执行中的综合能力
- 综合衡量成功率、速度与成本
- 单任务Token消耗可达数十万量级
正因如此,PinchBench的评测周期更长、资源消耗更高,能够真正体现模型在复杂真实场景中的综合能力与稳定性。
SCOUT:让大模型学复杂任务,省60%算力
Sage能够以3B激活参数实现云端级能力,核心功臣之一是商汤绝影自研的SCOUT技术(Sub-Scale Collaboration On Unseen Tasks,分级协同学习框架)。
技术原理
很多复杂任务涉及空间规划、设备联动、多步决策,直接让大模型自己试错学习,既慢又烧算力。SCOUT的解决思路是”探路与吸收解耦”:
- 小模型先探路:派一个轻量小模型快速在任务里跑一遍,把走得通的路径筛选出来
- 大模型再吸收:把这些高价值经验喂给大模型学习,形成”小模型先探路,大模型再吸收”的学习机制
实际效果
在复杂任务能力注入过程中,SCOUT可节省约60%的GPU小时消耗。这意味着,在同等算力预算下,可以训练更多、更复杂的任务能力;在同等任务需求下,可以大幅降低训练成本。
ERL:让模型自己擦掉错误步骤
第二个核心技术是ERL(Erasable Reinforcement Learning,可擦除强化学习),该技术已被机器学习顶级会议ICLR 2026收录。
技术原理
用户在真实使用中提出的需求,往往需要模型跨多个步骤完成推理和执行。中间一旦某一步出现偏差,整个任务流程就可能失效。ERL让模型能够自动识别推理过程中的错误步骤,对错误内容进行”擦除”并重新生成,从源头阻断偏差扩散。
这就像给模型装上了”边想边纠错”的能力——不是等做完才发现错了,而是随时能够回溯、修正、重来。
实际效果
在多跳复杂推理基准上,ERL较此前SOTA取得显著提升。装车后,Sage在复杂任务上的完成率提升了20%。
端云协同:重新定义智能座舱
Sage的实力已在评测中得到验证,但它真正改变的是智能座舱的体验范式。
从”听懂指令”到”说到做到”
传统座舱AI的交互模式是”一问一答”:用户说”帮我导航到最近的加油站”,AI执行指令,交互结束。Sage驱动的座舱AI则能够处理更复杂的任务链:”明天出差去上海,帮我规划行程,包括机票、酒店和会议地点的导航”,AI能够理解这个复合意图,自动拆解为多个子任务并依次执行。
端云协同的最优解
Sage并不是要完全替代云端模型,而是实现了端云之间的最优分工:
- 端侧:执行高频、低延迟、涉及隐私的简单任务
- 云端:处理复杂推理、需要最新知识的任务
两者协同,既保证了响应速度,又确保了能力上限。
在北京车展期间,商汤绝影将正式推出搭载Sage端侧多模态智能体基座大模型的Sage Box,为汽车迈入超级智能体时代筑牢核心根基。
技术深水区的启示
Sage的成功,给行业带来几点重要启示:
1. 架构创新比参数堆砌更重要
通过MoE架构和后训练技术的优化,Sage用3B激活参数实现了远超预期的能力。这说明,在端侧场景下,与其追求更大的参数量,不如在架构层面进行更精细的设计。
2. 数据质量决定能力上限
SCOUT和ERL这两项技术,本质上都是在解决”如何让模型更高效地学习正确能力”的问题。这提示我们,在算力受限的情况下,高质量的训练数据和高效的学习方法,可能比单纯增加算力更有效。
3. 评测体系需要与时俱进
PinchBench这类面向真实Agent工作流的评测体系,正在成为评估AI能力的新标准。它提醒我们,AI能力的进步不能只看”考试分数”,更要看”实战表现”。
写在最后
当3B参数的端侧模型开始在PinchBench上超越云端旗舰,我们看到的不仅是商汤绝影的技术突破,更是整个AI产业的一个转折点:
端侧AI正在从”能用”走向”好用”,从”简单指令”走向”复杂任务”,从”辅助工具”走向”智能伙伴”。
这个转变意味着,AI智能体不再只是云端大厂的专属能力,而是开始真正”飞入寻常百姓家”。未来的手机、汽车、家电,或许都将具备真正意义上的AI智能体能力——而不仅仅是”会说话的音箱”。
Sage迈出了这一步,而这一步的意义,可能远超我们今天的想象。
相关阅读:
发表回复